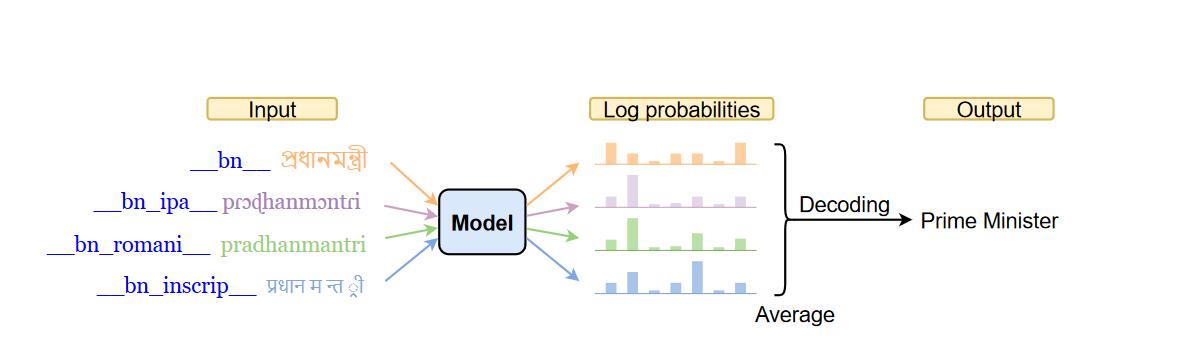
fairseq的使用入门
fairseq常用命令
通用命名参数
| 命令 | 参数 | 用法 | 可选项/备注 |
|---|---|---|---|
| 通用命名参数 | --no-progress-bar |
关闭进度条 | 默认:False |
--log-interval |
每N批记录进度(禁用进度条时) | 默认:100 | |
--log-format |
选择日志格式 | 选项:json,none,simple,tqdm | |
--log-file |
指定输出metric的日志文件 | ||
--tensorboard-logdir |
tensorboard的日志文件位置 | 须和-–logdir of running tensorboard相同,默认无日志 | |
--wandb-project |
用于日志的权重和偏置项目名 | ||
--seed |
设置随机数种子 | 默认为1 | |
--cpu |
使用CPU而不是CUDA | 默认:False | |
--tpu |
使用TPU而不是CUDA | 默认:False | |
--bf16 |
使用数据格式bfloat16,前提—tpu | 默认:False | |
--memory-efficient-bf16 |
使用内存高效的bfloat16,前提—bf16 | 默认:False | |
--fp16 |
使用数据格式FP16 | 默认:False | |
--memory-efficient-fp16 |
使用数据格式内存高效的FP16, | 默认:False | |
--fp16-no-flatten-grads |
不展开FP16梯度tensor | 默认:False | |
--fp16-init-scale |
默认:False | ||
--on-cpu-convert-precision |
浮点数转化为fp16/bf16将在CPU上完成. | 默认:False | |
--amp |
使用自动混合精度 | 默认:False | |
--usr-dir |
包含个性扩展的模块路径(tasks/architectures) | ||
--empty-cache-freq |
pytorch CUDA缓存清理频率 | 默认:0(不清理) | |
--model-parallel-size |
使用并行的GPU数量 | 默认:1 | |
--quantization-config-path |
quantization配置文件路径 | ||
--criterion |
损失函数 | 默认:交叉熵 | |
--tokenizer |
分词工具 | 可选:mosses,nltk,space | |
--bpe |
bpe分词 | 可选:byte_bpe, bytes, characters, fastbpe, gpt2, bert, hf_byte_bpe, sentencepiece, subword_nmt | |
--optimizer |
优化器 | 可选:adadelta, adafactor, adagrad, adam, adamax, composite, cpu_adam, lamb, nag, sgd | |
--lr-scheduler |
学习率管理 | 可选:cosine, fixed, inverse_sqrt, manual, pass_through, polynomial_decay, reduce_lr_on_plateau, step, tri_stage, triangular,默认:fixed | |
--scoring |
评价指标 | 可选:bert_score, sacrebleu, bleu, chrf, meteor, wer,默认:bleu | |
--task |
任务选项 | 可选:multilingual_language_modeling, speech_unit_modeling, hubert_pretraining, translation等,默认:translation | |
--dataset-impl |
处理数据集方式 | 可选:raw, lazy, cached, mmap, fasta, huffman,默认:mmap |
命名参数省略:
- aim-repo
- aim-run-hash
- azureml-logging
- fp16-init-scale
- fp16-scale-window
- fp16-scale-tolerance
- min-loss-scale
- threshold-loss-scale
- amp-batch-retries
- amp-init-scale
- amp-scale-window
- all-gather-list-size
- profile
- reset-logging
- suppress-crashes
- use-plasma-view
- plasma-path
fairseq-preprocess参数
| 命令 | 参数 | 用法 | 可选项/备注 |
|---|---|---|---|
| fairseq-preprocess | 数据预处理:建词典并将训练数据二进制化 | 以下为预处理命令 | |
-s, --source-lang |
源语言 | ||
-t, --target-lang |
目标语言 | ||
--trainpref |
两个语言的训练文件前缀 | ||
--validpref |
两个语言的验证文件前缀 | ||
--testpref |
两个语言的测试文件前缀 | 说明:例如我们的数据中只有训练数据和测试数据,且文件后缀为src和tgt,即train.src、train.tgt、test.src和test.tgt,那么通过指定—source-lang src —target-lang tgt —trainpref train —testpref test,也可以读取的对应的文件。 | |
--align-suffix |
对齐后缀 | 未知 | |
--destdir |
输出文件位置 | 默认:data-bin | |
--thresholdtgt |
将目标语言出现次数少于阈值的词映射到unkown | 默认:0 | |
--thresholdsrc |
将源语言出现次数少于阈值的词映射到unkown | 默认:0 | |
--tgtdict |
重复使用给定的目标语言字典 | ||
--srcdict |
重复使用给定的源语言字典 | ||
--nwordstgt |
目标语言中需要retain的词数量,(解决oov问题) | 默认:-1 | |
--nwordssrc |
源语言中需要retain的词数量 | 默认:-1 | |
--alignfile |
对齐文件(可选) | 翻译 文字一一对齐 | |
--joined-dictionary |
生成联合的字典 | 默认:False | |
--only-source |
只处理源语言 | 默认:False | |
--padding-factor |
填充字典数量为N的倍数 | 默认:8 | |
--workers |
并行进程数量 | 默认:1 | |
--dict-only |
只构建字典 | 默认:False |
fairseq-train参数
| 命令 | 参数 | 用法 | 可选项/备注 |
|---|---|---|---|
| fairseq-train | 在一个或多个GPU上训练模型 | 以下为训练命令 | |
| 数据集加载 | --num-workers |
加载数据的并行进程数量 | 默认:1 |
--skip-invalid-size-inputs-valid-test |
忽略验证集和测试集中太长或太短的句子 | 默认:False | |
--max-token |
一个batch中tokens的最大数量 | ||
--batch-size,--max-sentences |
batch size | ||
--required-batch-size-multiple |
要求batchsize是该值的倍数 | 默认:8 | |
--required-seq-len-multiple |
要求最大序列长度是该值的倍数 | 默认:1 | |
--data-buffer-size |
预先加载的batch数量 | default:10 | |
--train-subset |
数据集中用于训练的子集 | 例如:trian,valid,test。默认:train | |
--valid-subset |
数据集中用于验证的子集 | 例如:trian,valid,test。默认:valid | |
--ignore-unused-valid-subsets |
do not raise error if valid subsets are ignored | 默认:False(未知) | |
--validate-interval |
每N个epochs在验证集上验证 | 默认:1 | |
--validate-interval-updates |
每N个updates在验证集上验证 | 默认:0 | |
--validate-after-updates |
在N次更新后才验证 | 默认:0 | |
--fixed-validation-seed |
设置验证时的种子值 | ||
--disable-validation |
取消验证 | default:False | |
--max-tokens-valid |
验证时每批次的最大tokens数 | 默认和 --max-tokens相同 |
|
--batch-size-valid |
验证时batchsize | 默认和--batch-size相同 |
|
--max-valid-steps,--nval |
评估的总batch数量 | ||
--curriculum |
在前N个epochs中不打乱batch | N默认:0 | |
--gen-subset |
选择生成的数据集子集(train,valid,text) | 默认:test | |
--num-shards |
N文件切片 | 默认:1 | |
--shard-id |
生成shards的其中第i个(i<num-shards) | 默认:0 | |
--grouped-shuffling |
在num_shards组中打乱批次,使得每个子进程中的序列长度相似,前提batches按照长度排序 | 默认:False | |
--update-epoch-batch-itr |
默认:False (未知) | ||
--update-ordered-indices-seed |
默认:False (未知) | ||
| 分布式训练 | --distributed-world-size |
设置所有节点的GPU总数,等于可见GPU数量 | 默认:1 |
--distributed-num-procs |
fork的子进程数量,等于可见GPU数量 | 默认:1 | |
--distributed-rank |
目前进程的级别 | 默认:0 (未知) | |
--distributed-backend |
分布式后端 | 默认:nccl (未知) | |
--distributed-init-method |
初始化方法 | (未知) | |
--distributed-port |
端口号,如果设置了上一条就不用管 | 默认:-1(未知) | |
--device-id,--local-rank |
使用哪一个GPU | 默认:0(未知) | |
--distributed-no-spawn |
即使有多个GPU也不生成多个进程 | 默认:False(未知) | |
--ddp-backend |
DistributedDataParallel后端 | 默认:pytorch_ddp | |
--fix-batches-to-gpus |
不要在gpu之间切换批次;这减少了整体的随机性,可能会影响精度,但避免了重新读取数据的成本 | 默认:False | |
--find-unused-parameters |
控制未使用参数检测 | 默认:False (未知) | |
--gradient-as-bucket-view |
默认:False (未知) | ||
--heartbeat-timeout |
如果N秒内进程没反应就Kill,N为-1的话不kill | 默认:-1 | |
--broadcast-buffers |
在GPU之间复制不可训练的参数 | 默认:False | |
--slowmo-momentum |
slowMo动量设置 | ||
--slowmo-base-algorithm |
基础算法sgd或localsgd | 默认:localsgd | |
--localsgd-frequency |
localsgd的allreduce频率 | 默认:3 | |
| 部分其他参数见文档 | |||
| 模型配置 | --arch -a |
模型架构选择 | 可选项项:transformer_tiny,transformer,transformer_iwslt_de_en, transformer_wmt_en_de,roberta_base… |
| 优化设置 | --max-epoch |
到特定的epoch时停止训练 | 默认:0 |
--max-upadte |
到特定的update时停止训练 | 默认:0 | |
--stop-time-hours |
到指定的小时数后停止训练 | 默认:0 | |
--clip-norm |
梯度剪切 | 默认:0 | |
--sentence-avg |
使用一批次的句子数量正则化梯度(而不是tokens数量) | 默认:False | |
--update-freq |
在第i个epoch时按照每Ni个批次更新参数 | 默认:1 | |
--lr |
在前N个epoch设置学习率,使用LR_N的话epochs>N | 默认:0.25 (未知) | |
--stop-min-lr |
当学习率降到该值时停止训练,默认不停止 | 默认:-1.0 | |
--use-bmuf |
使用全局优化器来同步多GPU/shards上的模型 | 默认:False | |
--skip-remainder-batch |
如果设置这个选项,则会跳过最后一批不满的批次 | 默认:False | |
| 检查点 | --save-dir |
保存检查点的路径 | 默认:checkpoints |
--restore-file |
加载已保存检查点文件的路径 | 默认:checkpoints | |
--continue-once |
从该检查点继续,除非设置了--restore-file |
||
--finetune-from-model |
从预训练模型微调 | 未知 | |
--reset-dataloader |
如果设置了,就不从checkpoints中加载dataloader state | 默认:False (未知) | |
--reset-lr-sheduler |
如果设置了,就不从checkpoints中加载lr sheduler state | 默认:False (未知) | |
--reset-meters |
如果设置了,就不从checkpoints中加载meters | 默认:False (未知) | |
--reset-optimizer |
如果设置了,就不从checkpoints中加载optimizer state | 默认:False (未知) | |
--save-interval |
每N个epoch保存checkpoint | 默认:1 | |
--save-interval-updates |
每N个epoch验证并保存checkpoint | 默认:0 | |
--keep-interval-updates |
保存上一个选项的最后N个checkpoints | 默认:-1 | |
--keep-interval-updates-pattern |
和上一条同时使用,不删除第k个checkpoints,其中k%keep_interval_updates_pattern==0 | 默认:-1 | |
--keep-last-epochs |
保存最后N个epoch的checkpoints | 默认:-1 | |
--keep-best-epochs |
保存N个最佳sorce的checkpoints | 默认:-1 | |
--no-save |
不保存model和checkpoints | 默认:False | |
--no-epoch-checkpoints |
只保存最后一个epoch和最佳的checkpoints | 默认:False | |
--no-last-checkpoints |
不保存最后一个epoch checkpoints | 默认:False | |
--no-save-optimizer-state |
不将optimizer state视为checkpoint的一部分 | 默认:False | |
--best-checkpoint-metric |
best checkpoint的标准 | 默认:loss (重要) |
|
--maximize-best-checkpoint-metric |
选择最大的metric value来保存最佳的checkpoints | 默认:False(未知) | |
--patience |
连续的N次验证性能没有提升则停止训练,会被–validate-interval影响 |
默认:-1 | |
--checkpoint-suffix |
检查点文件的后缀 | 默认:空 | |
--checkpoint-shard-count |
如果checkpoints文件超过300GB,会将其切片防止存储不足。 | 默认:1 | |
--load-checkpoint-on-all-dp-ranks |
在所有并行设备上加载checkpoints,从第一个 | 默认:False | |
--write-checkpoints-asynchronously, --save-async |
异步保存检查点,功能测试中 | 默认:False |
fairseq-generate参数
| 命令 | 参数 | 用法 | 可选项/备注 |
|---|---|---|---|
| fairseq-generate | 使用已训练的模型翻译预先处理好的数据 | ||
| Generation | --path |
模型文件路径,冒号间隔 | |
--post-process,--remove-bpe |
去除BPE、字母分割等 | ||
--quiet |
只输出最后的分数 | 默认:False | |
--model-overrides |
在生成时重载模型参数,替换训练时的参数 | 默认:无 | |
--results-path |
保存评价结果的路径 | ||
--beam |
beam size | 默认:5 | |
--nbest |
输出翻译的结果数 | 默认:1 | |
--max-len-a |
生成句子最大长度ax+b,x是源句子长度 | 同下使用,默认:0 | |
--max-len-b |
生成句子最大长度ax+b,x是源句子长度 | 同上使用,默认:200 | |
--min-len |
最小的生成长度 | 默认:1 | |
--match-source-len |
生成的句子长度和原句子长度相同 | 默认:False | |
--unnormalized |
compare unnormalized hypothesis scores | 默认:False(未知) | |
--no-beamable-mm |
在attention layers中不使用BeamableMM | 默认:False | |
--lenpen |
长度惩罚,如果小于1.0倾向短句子,大于1.0则倾向长句子 | 默认:1 | |
--unkpen |
未知单词惩罚,如果小于0产生更多unks,大于0产生更少 | 默认:0 | |
--replace-unk |
替换unk,使用字典 | ||
--sacrebleu |
使用sacrebleu | 默认:False | |
--score-reference |
只给参考翻译打分 | 默认:False | |
--prefix-size |
给定前缀长度来初始化生成 | 默认:0(未知) | |
--no-repeat-ngram-size |
ngram中不能重复生成 | 默认:0(未知) | |
--sampling |
在假设中采样而不是使用beam search | 默认:False | |
--sampling-topk |
从K个可能的下个字中采样而不是从全部词中采样 | 默认:-1 | |
--constraints |
词法约束解码过程 | 可选:ordered,unordered(未知) | |
--temperature |
temperature for generation | 默认:1.0 (未知) | |
--diverse-beam-groups |
组数 | 默认:-1(未知) | |
--diverse-beam-strength |
strength of diversity penalty for Diverse Beam Search | 默认:-1(未知) | |
--diverse-rate |
strength of diversity penalty for Diverse Siblings Search | 默认:-1(未知) | |
--print-step |
输出steps | 默认:False | |
--decoding-format |
解码格式 | 可选:unigram, ensemble, vote, dp, bs | |
--no-seed-provided |
设置了,生成时就不初始化种子 | 默认:False | |
--eos-token |
设置停止的token |
generation省略:
- print-alignment
- lm-path
- lm-weight
- iter-decode-eos-penalty
- iter-decode-max-iter
- iter-decode-force-max-iter
- iter-decode-with-beam
- iter-decode-with-external-reranker
fairseq可扩展部分
Tasks
Tasks存储字典,并且对加载/迭代数据集提供帮助,初始化Model/Criterion,计算损失。用法示例如下: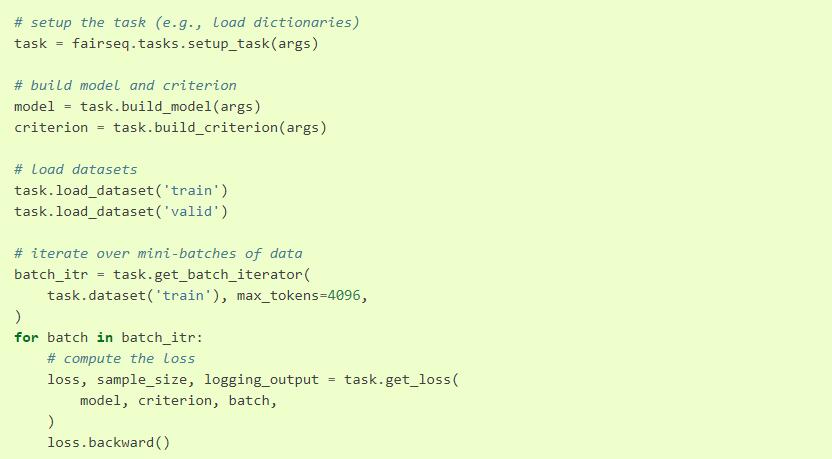
| 命令 | 参数 | 用法 | 可选项/备注 |
|---|---|---|---|
| Additional command-line arguments | 待续未完 |
Models
该部分定义网络前馈过程,封装可学习参数,可以设置模型架构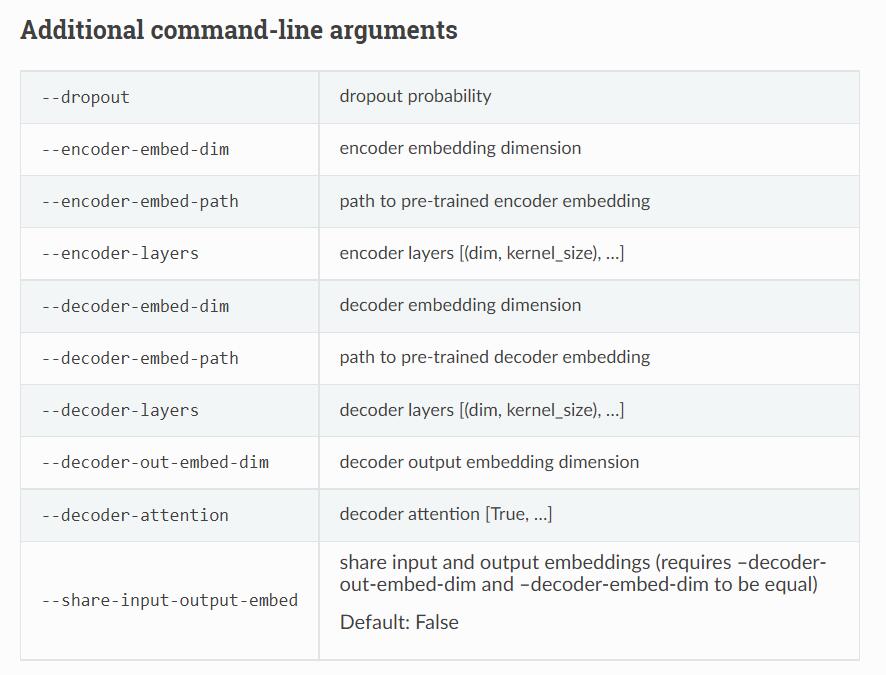
Criterions
给定model和batch,计算损失函数
Optimizers
根据梯度更新模型参数
学习率管理
数据加载和处理
模型模块
fairseq-translation使用
1 | # Download and prepare the data |
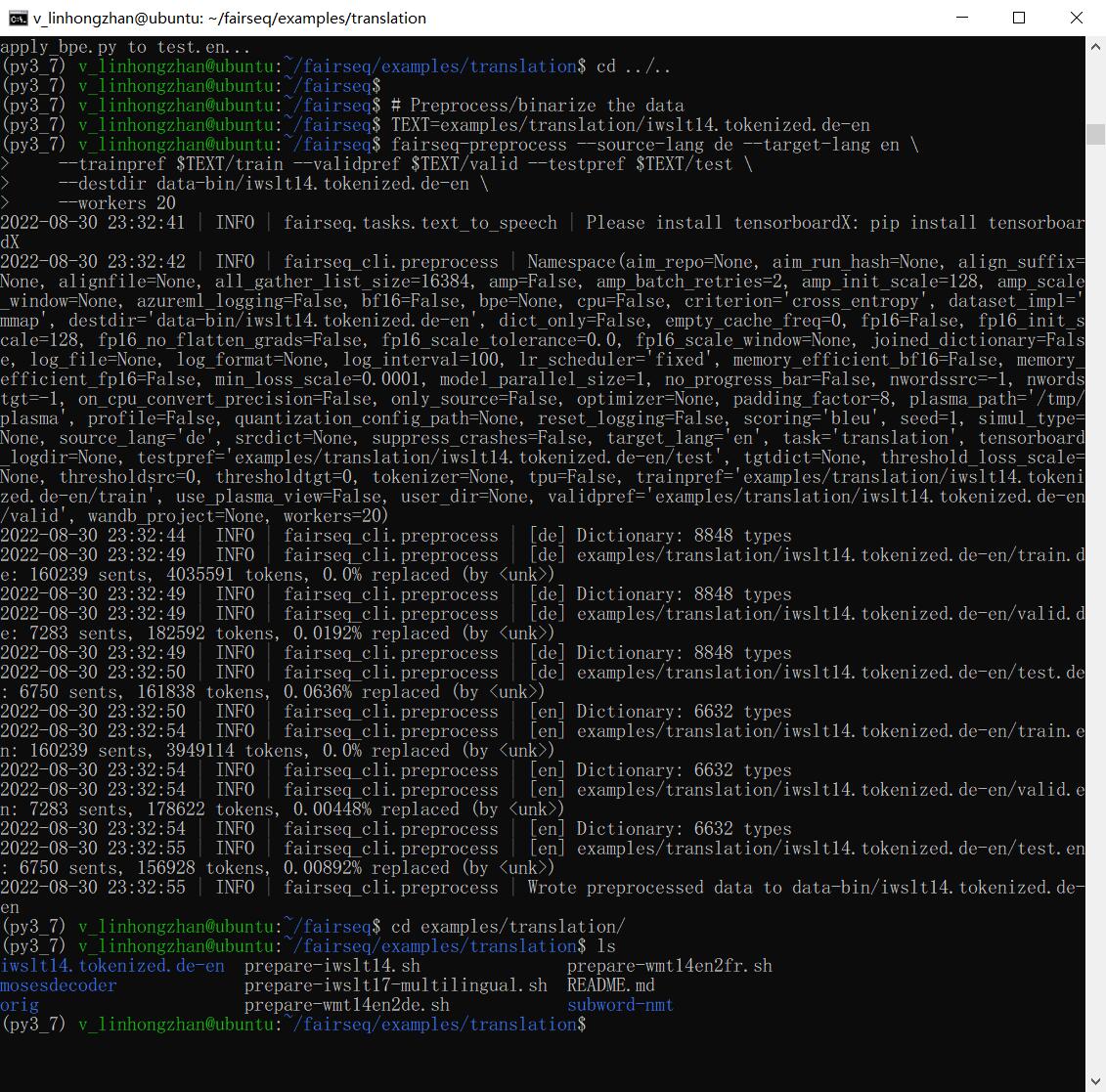
1 | CUDA_VISIBLE_DEVICES=0 fairseq-train \ |
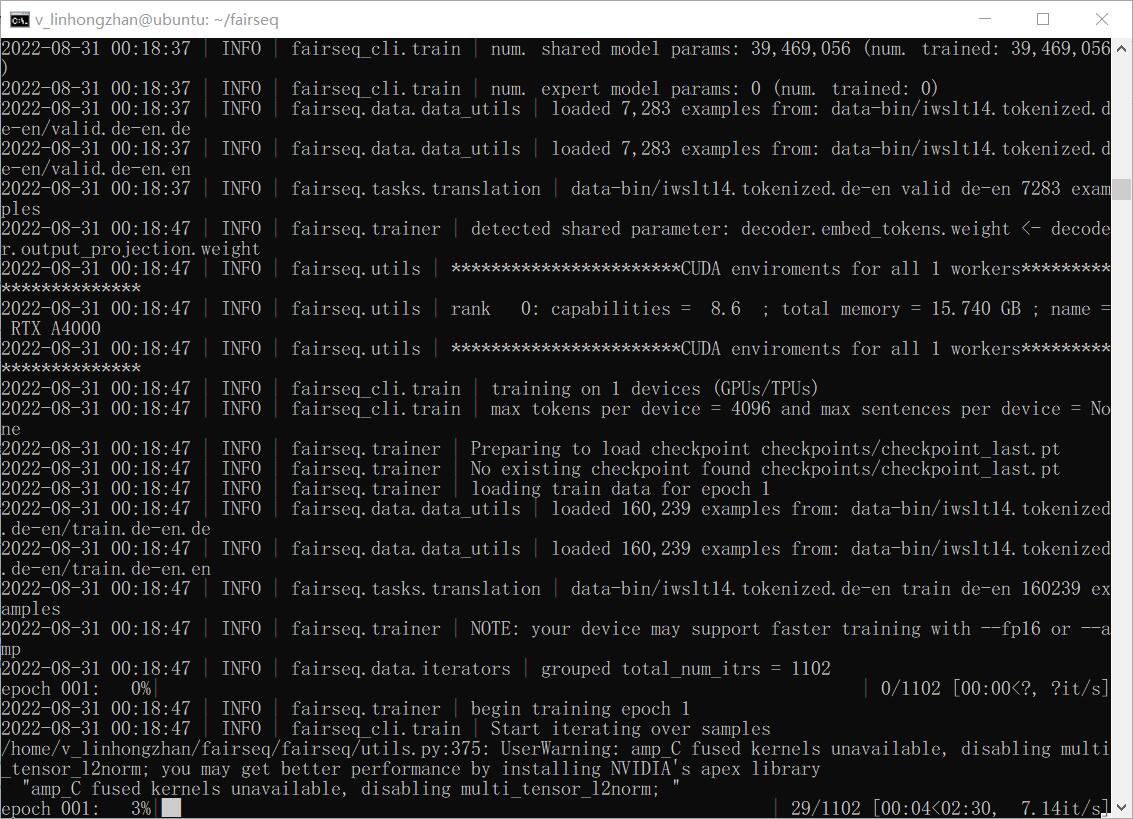
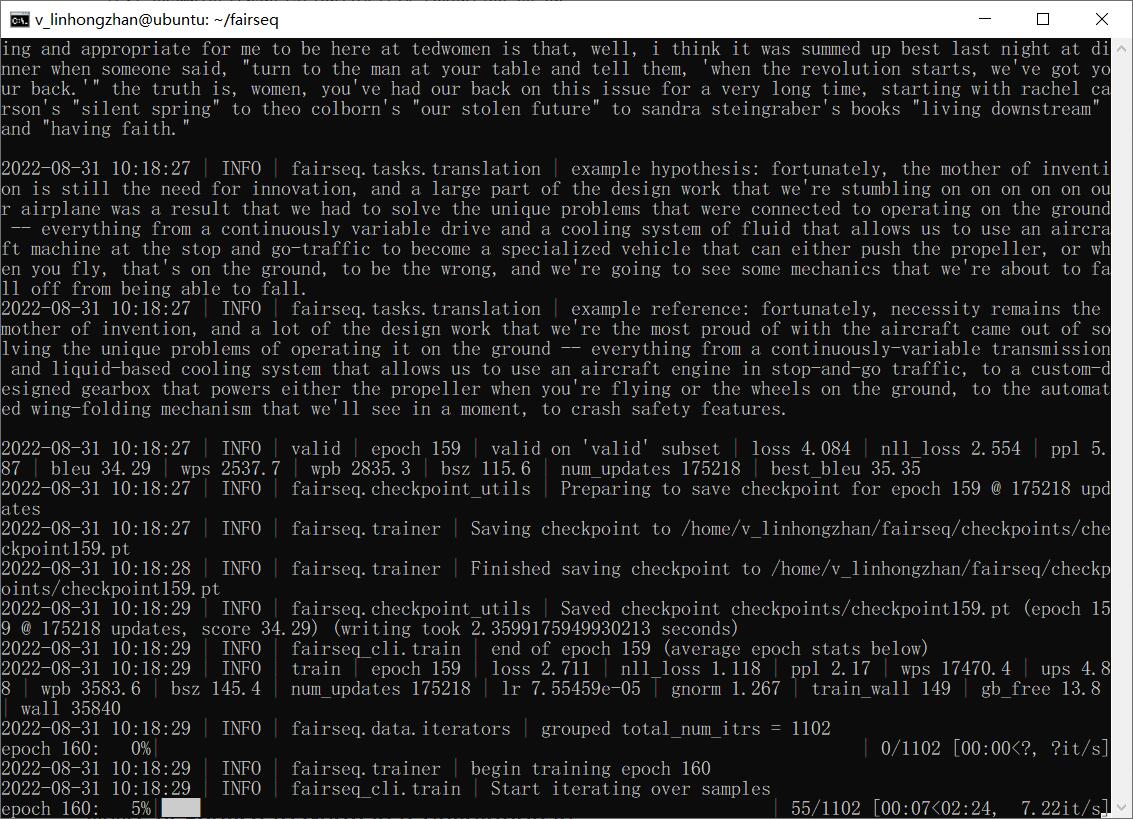
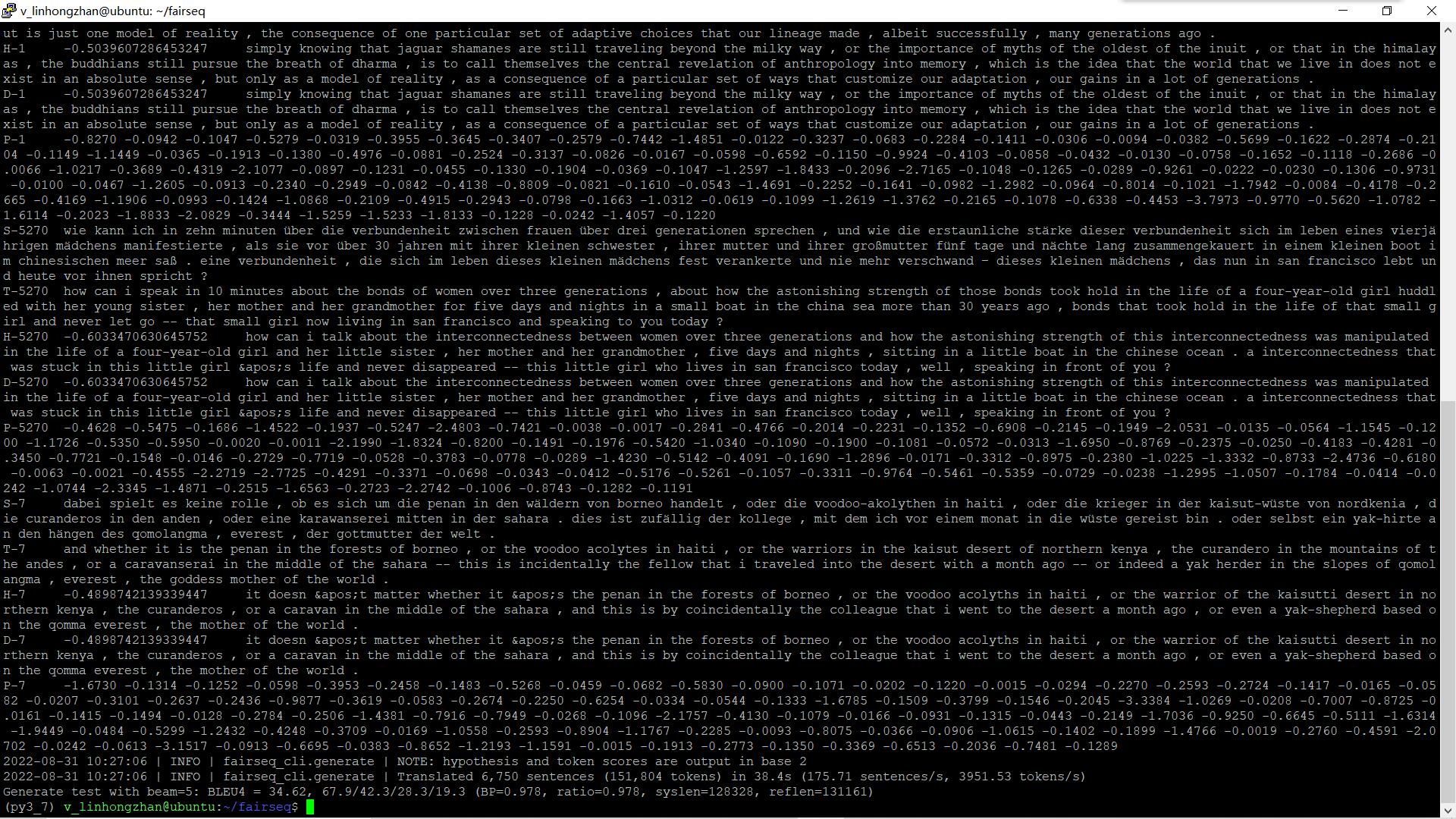
1 | fairseq-generate data-bin/iwslt14.tokenized.de-en \ |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 樱岛何处有麻衣!
 alipay
alipay