Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
前情提要
MMT对低资源语言来说很有用,因为在模型可以利用不同语言的相似性和不同语言之间的共享信息来提高低资源语言的翻译效果。对于不同语言的共享信息这一点来说,最基本的就是两个语言之间的重叠tokens,这些tokens通常含有相同的含义,低资源语言的翻译能借鉴模型中存储的高资源语言的信息。如果语言间的重叠很少:例如只有标点符号和数字,那么就没办法有效利用这部分信息。此外,如果两种语言处于不同书写的字体系统时,重叠也会很少。
语言共享信息方法
为了解决由于不同书写系统(scripts、writting systems)引起的不同语言之间的重叠太少问题,作者提出了以下三种信号转化方法(transliteration、signal system)
国际音标法
很多语言中的许多词发音是相同的,但是在不同的书写系统来看他们是完全不重叠的。因此为了运用这部分重叠的信息,将文本通过国际音标转为音标文本,其中音标的单位是音素。当然这种方法也会引入噪声,例如:
- 标点符号可能在转化过程中丢失(或许可以标记增加断句信息?)
- 对于一种语言来说不同词可能会发相同的音,但是是完全的不同字形。
- 一个字可能还有不同发音,不同发音的意思不同(个人想法)
罗马化法
在现代化过程中,很多语言都能通过键盘上的26个字母输入到电脑中,因此语言或多或少具有这种罗马形式(例如汉字拼音)。
转化为其他语言字体法
之前两种方式会增加模型需要学习的语言表示量,并且词汇表也要相应扩充。这种方法是将一种语言转化为同源语言族中一种语言,这样也不需要提前学习subword等。
优点
利用这三种方法不需要额外的模型,例如第一种方法可以直接使用音标对齐直接转化(可以利用工具包espkea-ng),第二种方法可以使用工具包indic-trans,第三种可以用字母表对齐实现(手动实现)。
多种转化后的信号融合
Straight Concatenation
简单,不需要改变模型架构,使用特殊的tokens分隔不同输入,代价是句子长的话就需要更多的计算。
Multi-Encoder Architectures
为每个信号准备一个Encoder,也就是多个Encoder,一个decoder模型,多个encoder组合方式不同,主要有4种(Libovick ́ y et al. (2018)),对应的encoder-decoder attention(cross attention)也有不同形式。虽然之前证明有效,但是还是需要更巧妙的模型设计才能达到更好的性能
Multi-Source Ensemble
多个模型,不同模型除了输入信号不同其他都相同,最后将每个模型输出的概率分布平均。缺点:超多计算。
Multi-Source Self-Ensemble
借鉴了集成多种信号的优点,但是只需要训练一个模型。对于一个句子来说,转为不同信号,每个信号前面加上特定的token,重复经过模型得到概率分布,最后将概率分布平均。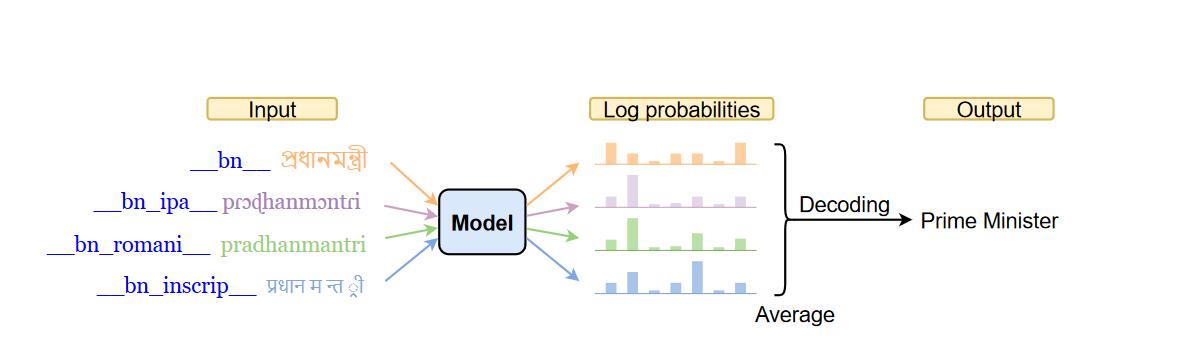
实验分析
翻译方向为XX->EN,语言族:Indic,Turkic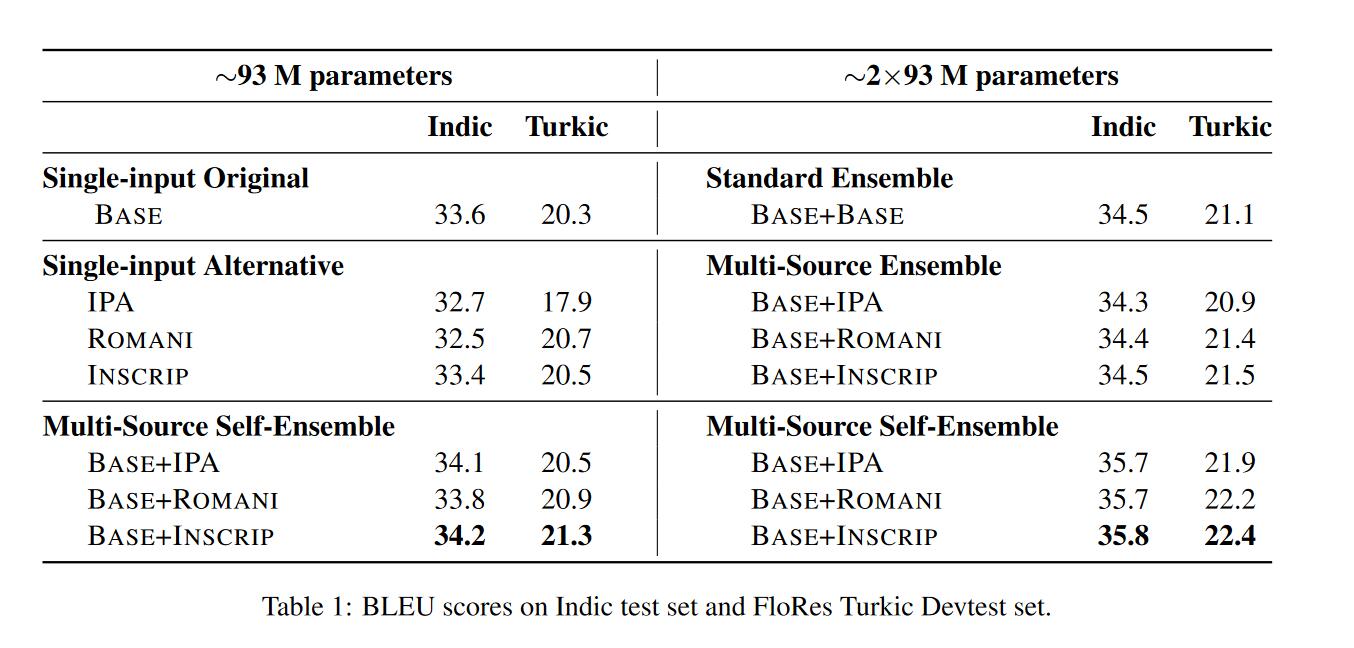
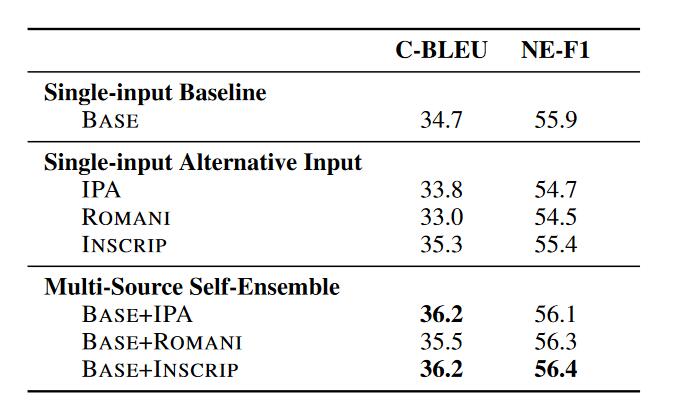
对于多源自集成来说:
- 单独的转化后的信号不会使得BLEU提升,甚至有些下降。原因是引入的干扰大于有效信息。
- 单独的转化后的信号和原始信号一起输入会使得BLEU提升,但是最多在1.0左右
- 将encoder参数量提升一倍,BLEU的值提升1.3。
多源自集成优势
- seq2seq模型架构不需要做改变
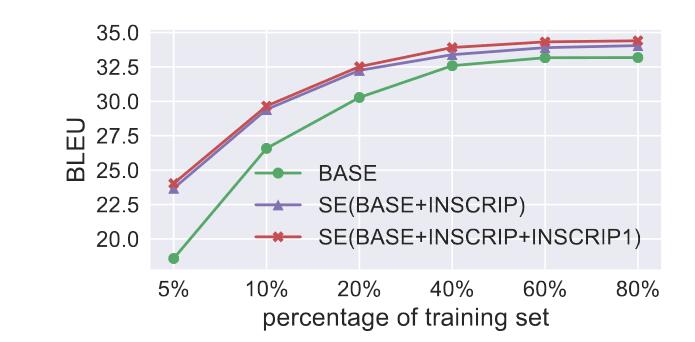
- 在低资源语料的情况下,比基线水平的BLEU提升更大达到5.0。并且随着数据集大小增大始终优于基线水平。
- 生成的假设较为一致,作者提出的C-BLEU更好(We treat the output of L1-En direction as reference and out-put of all other Li-En directions as hypothesis. We compute this for all N source languages in the dataset, accounting for total N (N − 1) C-BLEU scores, then take the average of all)
- 生成的句子使用NER去抽取实体,不同类别的实体识别的效果都优于基线。表明生成句子更准确。
结论
作者为了解决不同语言之间信息重叠过少的问题,提出了三种不同的信号转化方式和多源自集成方法使得翻译性能提升,准确性也有提升。
 alipay
alipay