Breaking Down Multilingual Machine Translation
Breaking Down Multilingual Machine Translation
前情摘要
(之前文章提到过,多对一的翻译方向设置比一对多的翻译对双语翻译的性能提高更高。)
此外之前还有很多分析多语言翻译的文章如(Kudugunta et al., 2019,Voita et al., 2019a,Aji et al., 2020,Mueller et al., 2020)对多语言翻译模型进行了一些分析,但是这些分析并没有去探究不同翻译方向(如many-to-one)对模型中不同组成的影响,也没有检查模型中不同组成(encoder/decoder)各自的影响。这就是这篇文章主要探索的两部分。
实验设置
数据集:TED Talks Dataset。将全部文本进行BPE分词,包括全部语言,词汇表32000。模型架构是Transformer。
多语言训练如何影响模型中各个部分
之前的实验表明,多语训练的模型比双语模型性能来的更好,为了探究到底是对encoder端还是decoder端有效,作者进行了实验。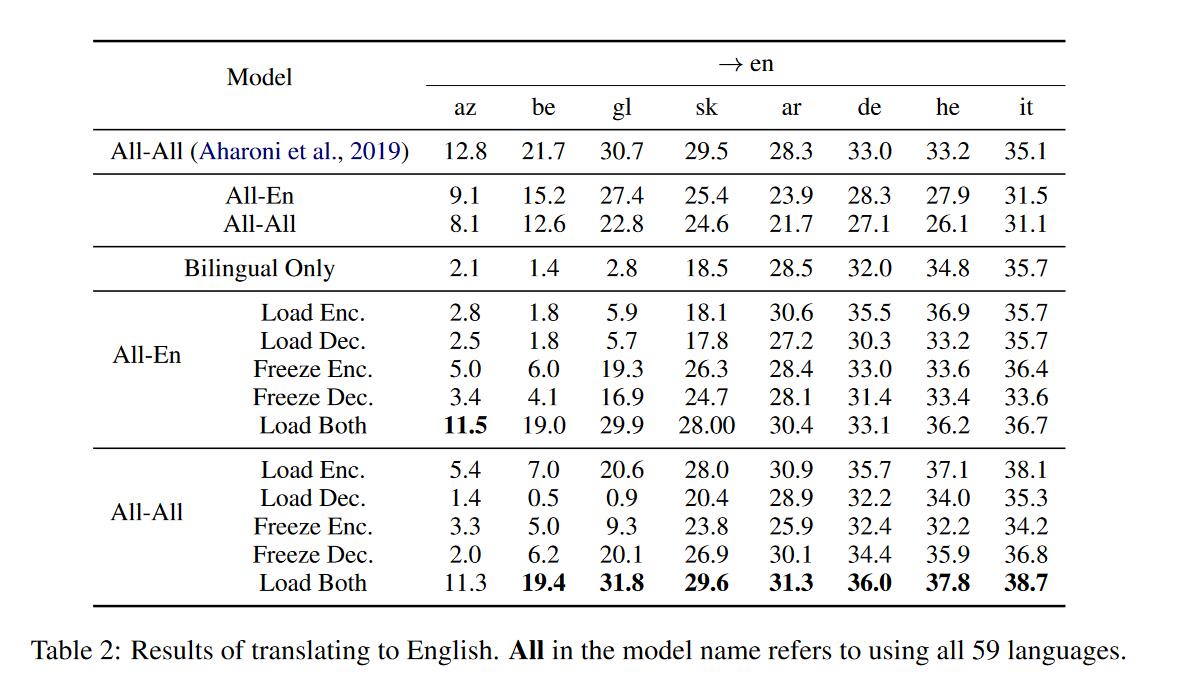
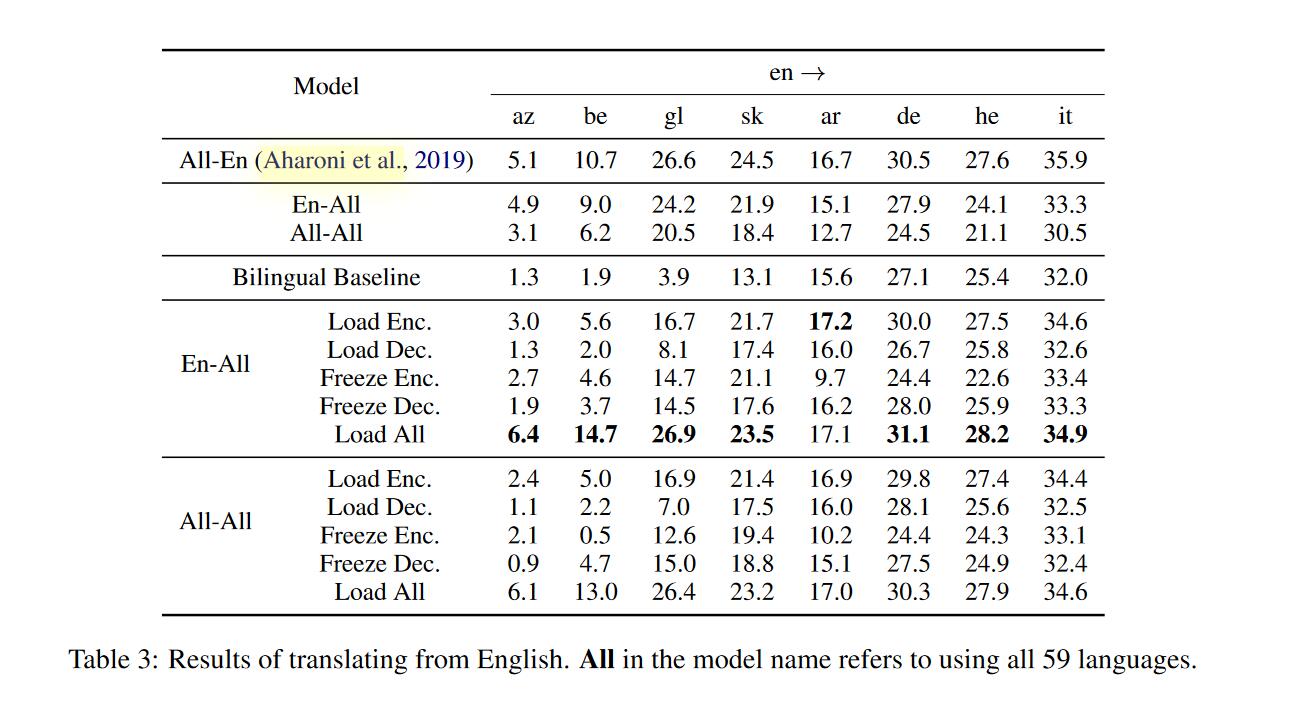
其中Bilingual Only是只使用双语语料并且从零开始训练的模型。Load xxx表示从训练好的多语言模型加载对应部分参数,并且这部分参数是可以训练的。Freeze xxx同样是加载对应参数但是冻结的,不可更新的。之所以提出freeze是因为可能模型其他部分的随机初始化会使得这部分的效果得到削弱。从左到右前4个是低资源语言,后4个是高资源语言。
实验结果分析
对低资源语言来说:
- 多语言训练通常对encoders和decoders都是有益的。
load Enc.和freeze Dec.再次证实encoders和decoders确实会保留多语言训练中的有效信息,比只用双语语料训练来的有效。 - 多语言训练对encoders来说更有效,load encoder和freeze encoder的表现优于load decoder和load decoder。’
对高资源语言来说:
- 多语言训练通常对encoders是有益的,但在部分情况下对decoders不是有益的,
load Enc.性能提升明显,但是在load Enc.和freeze Dec.表现不比基线好。 - 多语言训练对encoder来的更重要,
load Enc.能得到更好的结果。
对两种类型语言来说
- load both普遍要比只load其中一种好。
- 对于
en->xx方向,load encoders会优于freeze encoders。对于xx->en方向,freeze decoders要优于load decoders(只有ALL-En中it->en不是,在低资源语言翻译上更明显)。前者证明了其实encoder端是和target language有关的。(因为load的话参数是会改变的,更有效地根据具体的语言将target language的信息加入到encoder中),后者有待思考
模型参数是如何共享于不同语言对
Head importance estimation(Michel et al. (2019))
该方法主要利用的是损失对应于每个头的梯度来衡量每个头的重要性。在每个attention中对各个头的梯度进行标准化后得到每个头的重要性得分,具体定义如下图:

对于一个Head来说,如果在两个语言对上的得分都很高的话,那么这个Head就是重要的并且是共享的。
结果分析
实验方法:一组语言对的所有训练句子可以得到相应的一组Head-importance得分,将其转为等级排序,对不同语言对来说就可以利用这两组数据计算斯皮尔曼等级相关系数。那么这个相关系数有什么用呢,怎么用来衡量模型中不同组成部分的共享情况呢? 答案就是:相关系数越高——>一致性越高——>参数共享程度越大。举例子说人话:比如有一部分参数P,语言对a在这上面的梯度(或importance score或者importance rank)和语言对b高度相似并且都很大的话,那么可以推测两个语言对在参数P上对结果(loss)的影响是高度相似的,反过来说也就是是参数P在不同语言对中是共享的。据此作者比较了encoder和decoder端的参数共享程度。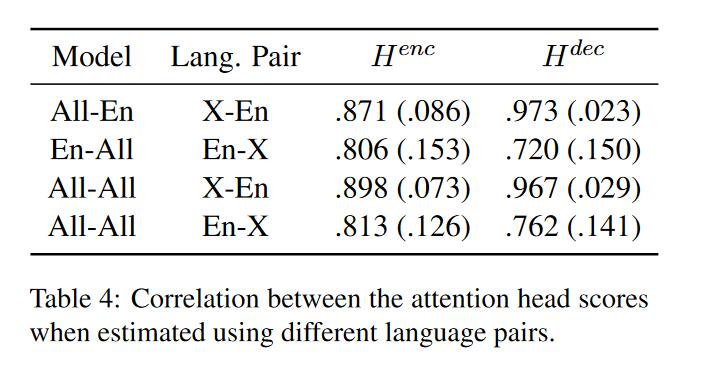
根据这个结果可以分析不同语言对之间的信息是如何在不同部分共享/存在的。
Encoder for En-X
对于encoders端来说,EN-X的语言对得到的相关系数(0.806和0.813)都要小于X-EN得到的相关系数(0.871和0.898)。这可能表明encoder端的部分参数是用来编码生成和目标语言有关的中间表示。
Encoder for X-En
X-EN得到的相关系数(0.871和0.898)都很高,说明encoder端是有可能高度参数共享的。
Decoder for En-X
虽然系数很低,但是在部分语言对中是共享的。对于一个模型来说尽可能是要在多语言中都有效。
Decoder for X-En
系数都很高,这表明decoder端参数是高度共享的。虽然之前文章有人证明encoder生成的中间表示是目标语言无关的,但是decoder端的重要参数取决于目标语言(也即需要这部分参数去学习目标语言之间不同之处),这就解释了多语言训练为什么不有利于XX-EN中decoder。其中的一个启发点就是如果要使得XX-EN翻译更好的话,多语言训练应该暴露更多的XX-EN语料,其中英文句子要更多样。
依据参数共享改进
对于多语言训练来说选择什么样的语言去训练会导致最后的双语翻译结果不一样,直觉上我们认为如果用相近的语言去预训练,最后得到的结果会更好。但有时候不是这样,用完全不相关的语言去训练可以达到更好的效果。因此怎么选择训练的语言成为一个重要问题,作者提出一种衡量标准,也就是要选择能够使得参数更好共享的语言。
Improving X-En by Related En-X Pairs
改进的思路,之前的实验说明对语言训练可能对decoder端的增益没有比encoder端大,这可能说明decoder端的参数共享程度比较低。所以我们可以通过选择使得decoder端的共享程度高的语言集合,具体计算如下:
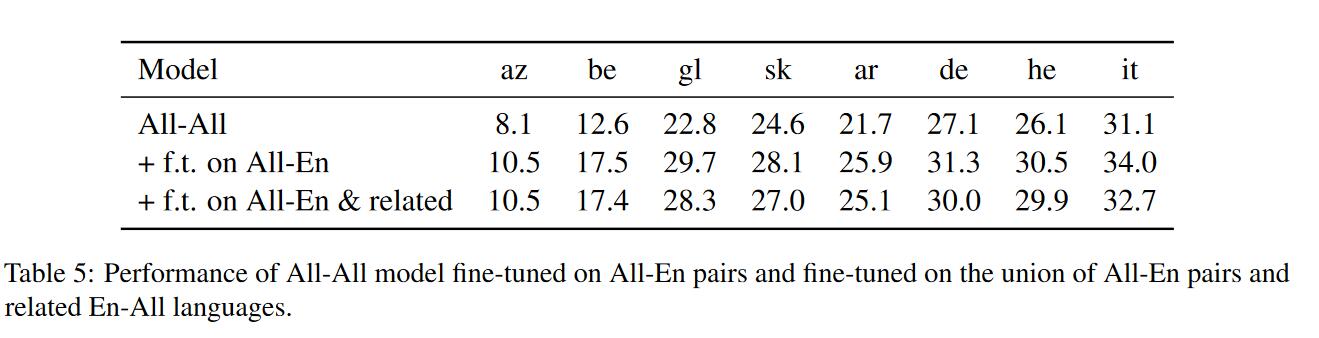
可以看到使用ALL-En语料微调的效果最好,其次是使用ALL-En语料+EN-ALL语料(其中ALL是计算得到的相关语言)。这也说明ALL-EN和EN-ALL训练语料如何使用会是一个难题,有待进一步探究和运用。
Improving En-X by Language Clusters
和上一种方法思路类似,要用相关的语言对改进EN-X的表现,逻辑:使用相关语言对——>能够使得参数共享越容易——>参数共享程度越高——>性能表现更好。
为了分析方便,作者使用t-SNE对一组head-importance scores进行降维,作者只关注decoders端的得分,因为decoders端的EN-ALL语料上的相关系数很低。降维完后,如果两种语言接近的话,那么作者认为其是相关的。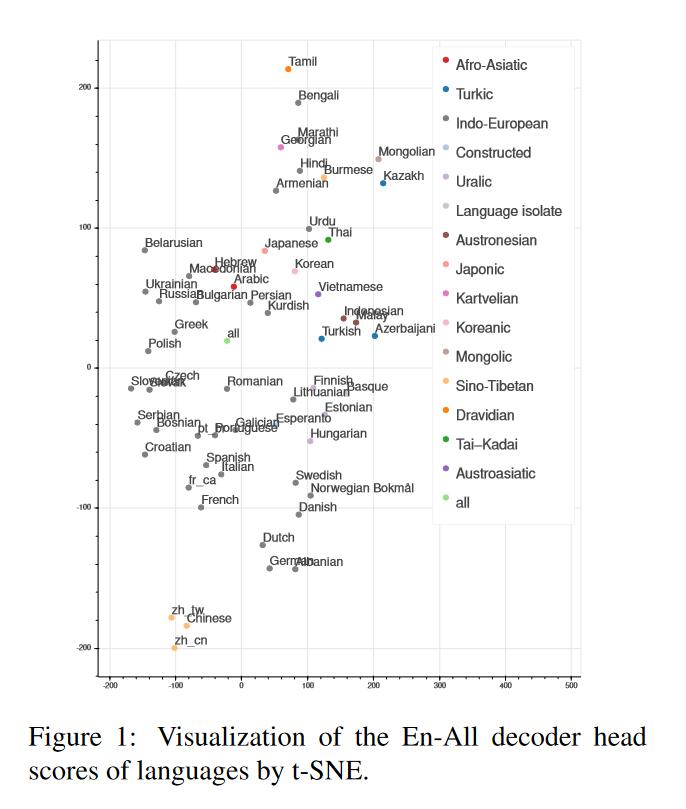
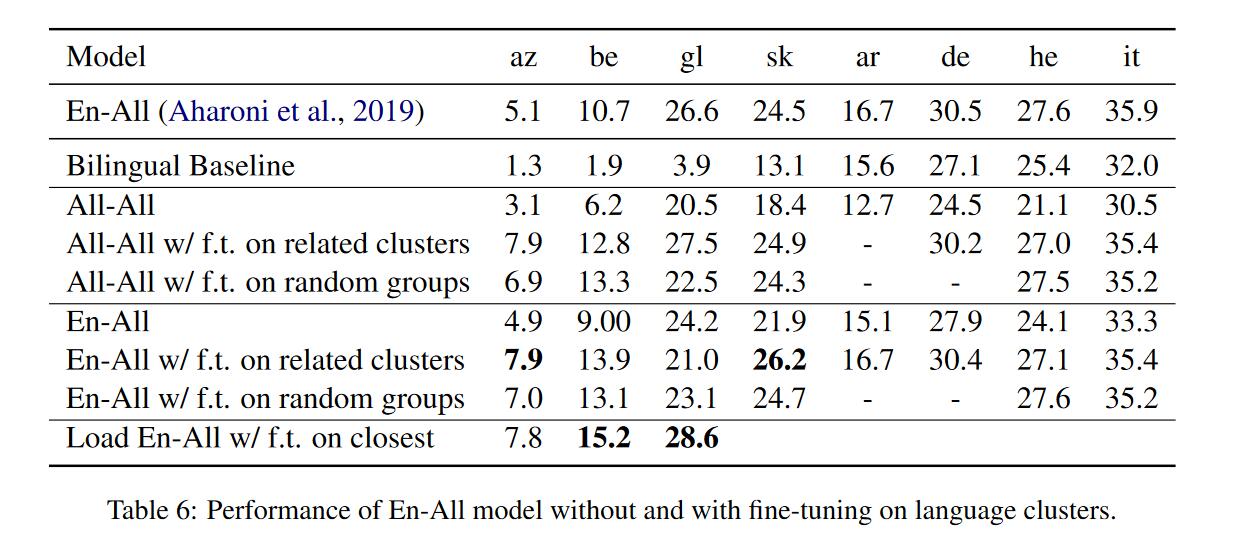
得到相近的语言族后作者进行了实验,得到以下结论
- 对于EN-ALL、ALL-ALL模型来说,在相近语言族上微调能够提升性能。
- 对于低资源语言来说总体在相近语言族上微调要优于在随机语言组上微调。
- 虽然图表中看起来使用相近的语言族并没有提升很多,这可能是因为相关系数阈值不够大,如果阈值选为0.8得到最后一行的结果,在两种方向语言翻译上得到较大提升。
为了验证这种使用语言族的方法会不会真的使得decoders端参数共享程度增加,作者进行了实验。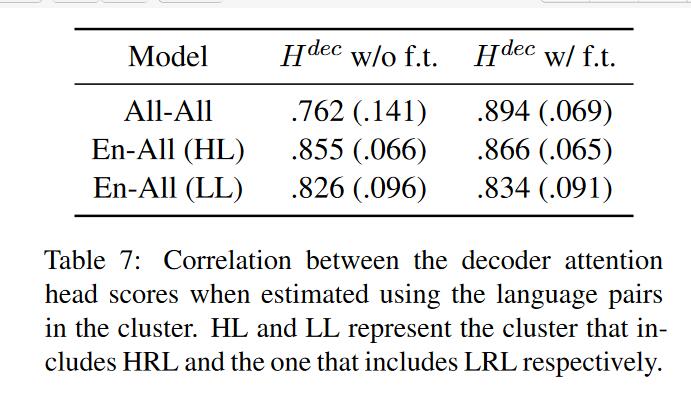
 alipay
alipay