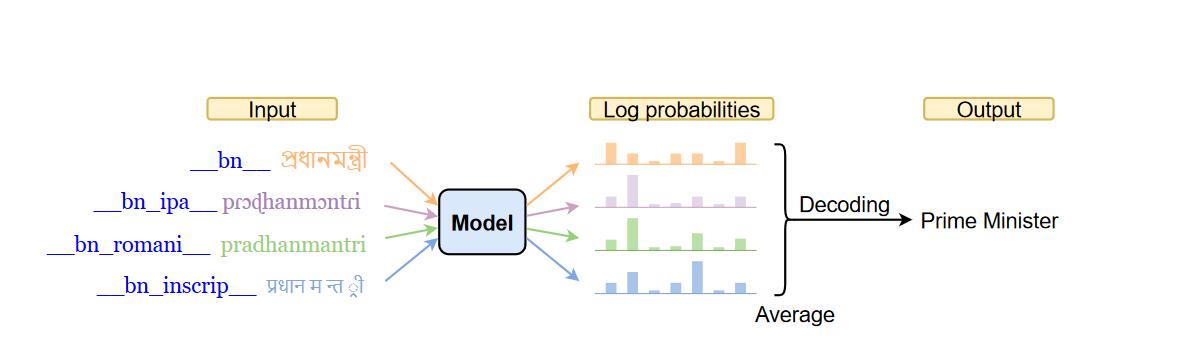
Pre-Trained Multilingual Sequence-to-Sequence Models: A Hope for Low-Resource Language Translation?
Pre-Trained Multilingual Sequence-to-Sequence Models: A Hope for Low-Resource Language Translation?
摘要
该篇论文主要以mBART(一种预训练端到端多语言模型)为模型架构探索数据集对性能的影响,也形成了一种衡量模型的数据敏感性的框架,经过实验,文章提出的一个结论是与其想着怎么微调模型,还不如从数据上改进以更大提升表现,增强实用性。
PMSS(预训练端到端多语言模型)数据集敏感性可探究的几个方面:
- 微调训练时所需的数据量
- 微调数据集中的噪声
- 预训练数据集数量
- 领域不匹配问题
- 语言类型问题
mBART模型介绍
首先这是一个纯用Transformer架构的预训练模型,预训练数据是Common Crawl,具有多种语言的文本数据。mBART的预训练目标是单语形式的,将原句子一定程度上破坏之后使用模型重建这个句子。这种目标函数比较有意思,它不引导模型产生相似的tokens或者representations。(疑问点,待续)在经过预训练后可以有监督或者直接进行翻译训练、预测。
实验部分
评测语言选择
文章选了10种语言,8种低资源语言和2种高资源语言(FR,HI)。在字体方面也有分类,主要为Latin和非Latin。在未知语言上也有分类,有4种语言是mBART在预训练未接触过的。具体统计如下图: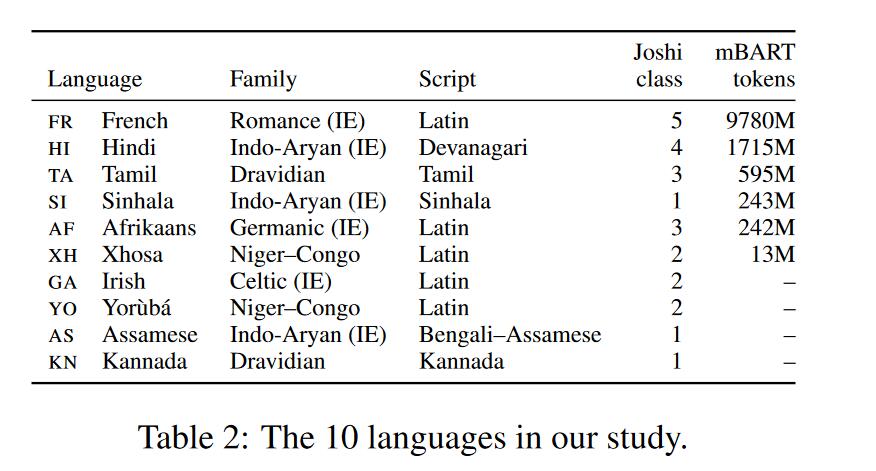
平行语料
语料选择上既有Common Crawl(数量大、开放域、使用自动对齐上可能有噪声)、Bible等。包括开放域和领域特定的语料、并且将训练数据按照数量大小进行切割以进行下一步实验。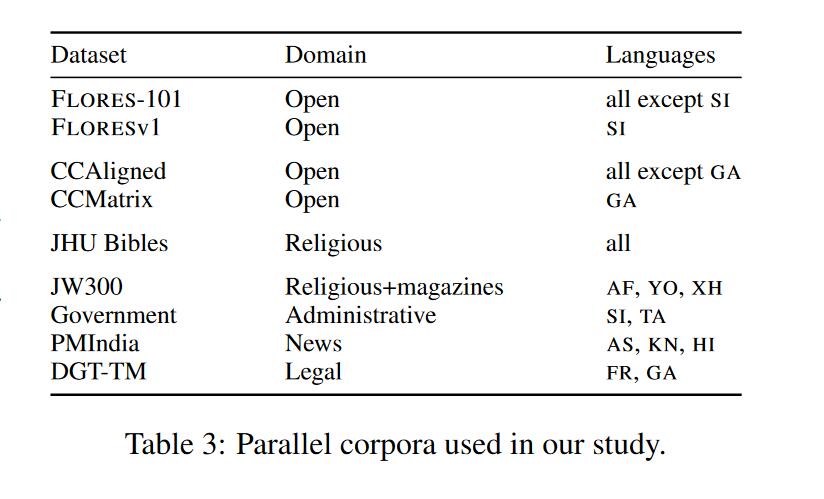
实验结果
实验以EN->XX和XX->EN为翻译方向。每个语言有3个测试集(2个特定域,FLORES是开放域),分别使用不同数量、不同类型的数据集进行微调训练得到结果。
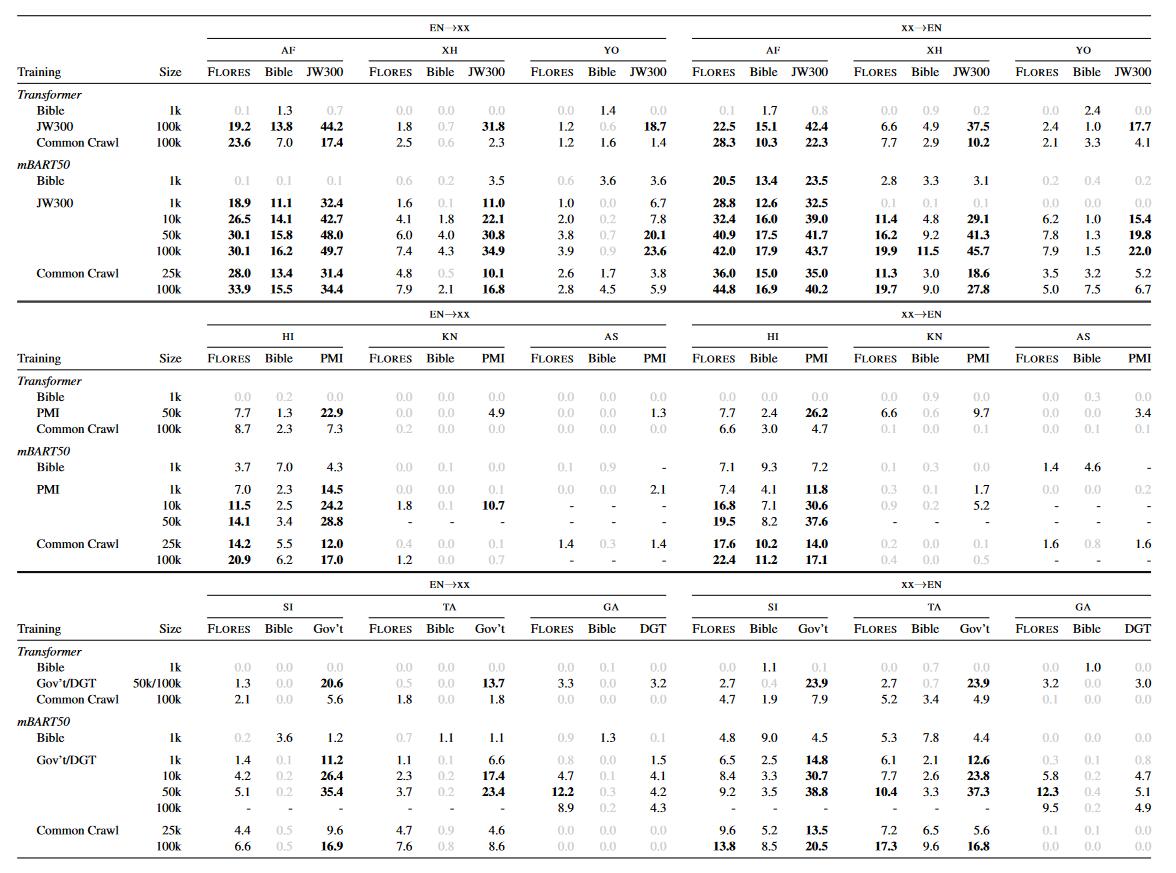
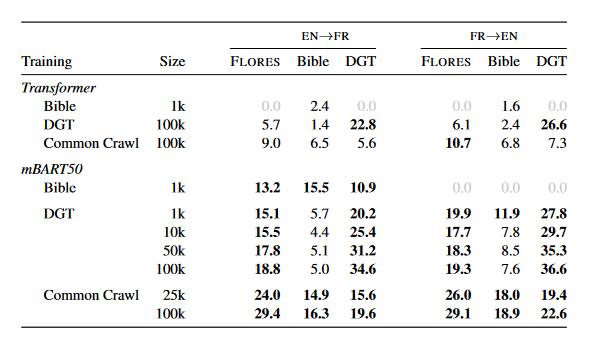
实验分析
微调训练时所需的数据量
- 使用Common Crawl(开放域),mBART模型使用25k的数据在性能上远超用100k数据的transformer模型,这在大多数语言上都得到验证,也有一两个低资源语言两者的表现都很不好。(test时候语言是预训练时就接触到的模型)
- 使用特定域的数据进行微调,结果也是mBART优于transformer。
- 微调训练的句子对数将在
50k左右达到一个饱和,数量加大的话会导致预训练的参数改变过多,预训练保留的信息被冲掉,(mBART是标准Transformer架构,参数量约680M,预训练语料远大于50k)
微调数据集中的噪声
这里噪声指的是是否和领域相关的数据。根据实验结果表明,mBART微调时相同领域的训练数据只需要开放域训练数据量的十分之一就能达到更好的效果。
预训练数据集数量
mBART模型比transfomer进步的地方在于性能提升上,高资源语言更显著,个人认为句法结构和词语的多样性对于数据集来说很重要,因为模型的可拓展能力可能不够,没办法像人一样举一反三。那对应语料的数据量越大涵盖的词语和句子更多变,使得模型能够更好的将语言特征通过预训练保存到参数中,反过来说mBART确实能够很好利用预训练学习到,因为观察出了不同语言的差异。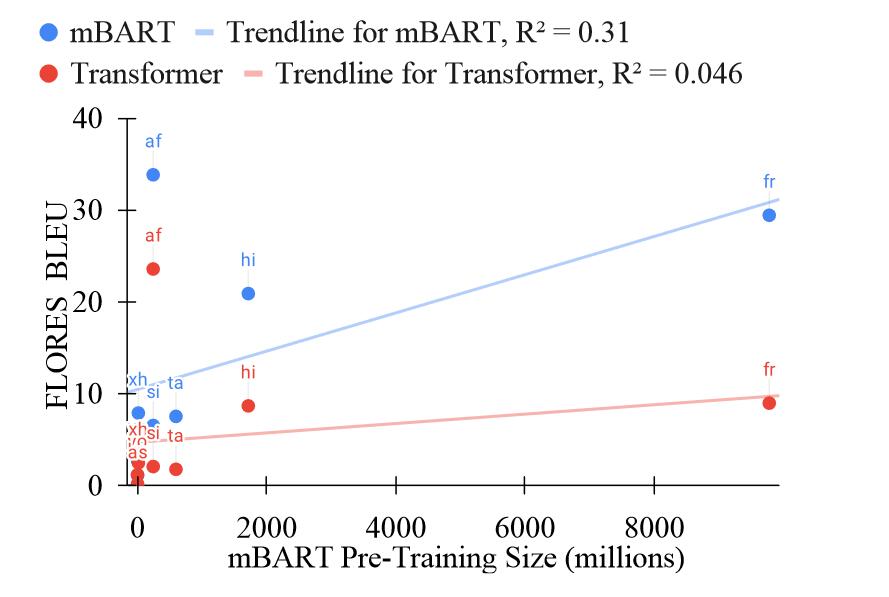
领域不匹配问题
- 领域相同的训练集和测试集效果要比不匹配的情况好。
- 开放域训练的模型可能在特定领域的测试集上表现得比开放域数据集好。
- 预训练数据越大越能在特定域数据集上表现出色,可以弥补特定域数据集不足的问题。
语言类型问题
- 如果一个低资源语言和目标语言有较多的token片段重叠或者相似的句法特征(主谓宾顺序、辅音突变等语法现象),那么在翻译的时候就可以得到更好的结果。
- 翻译成英语总比英语翻译成其他语言的BLEU要好。这可以说是decoder更好地学到了英语这个语言,也有可能是由于BLEU不将子词纳入计算范围,这导致有些词素是对的但是整个词错了,从而导致翻译成其他语言的BLEU值不高。
总结
- 对于开放域的翻译来说,mBART比原始transformers架构只需要更少的微调数据就能达到更好的效果(
4-10倍) - 对于特定域的翻译来说,mBART数据量有效性为
5-10倍,并且同时也更鲁棒,在领域外表现更好。 - 对于预训练数据集中没有出现的语言来说,BLEU表现非常差劲基本用不了。
对于标题给出的疑问,PMSS能不能改善低语言资源,作者的回答是与其想着怎么微调模型,还不如想想怎么为低资源数据收集更多更好的训练句子(寄,不知道后面有无后续PMSS的文章)
 alipay
alipay