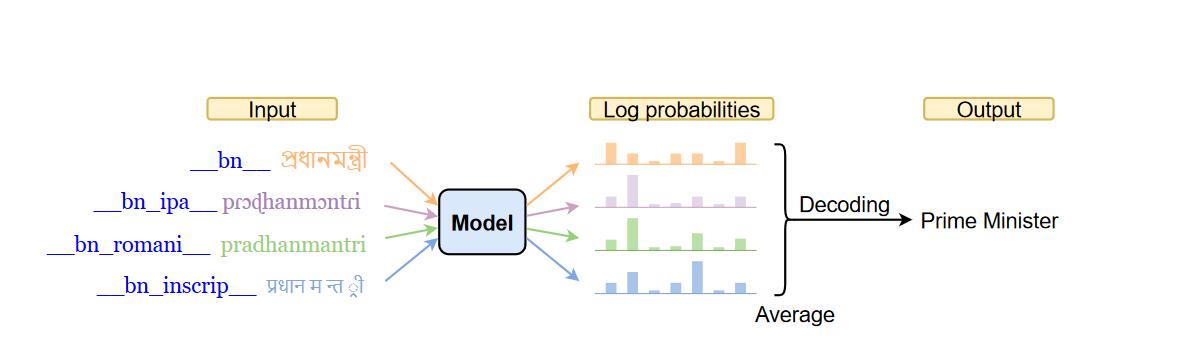
Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation
前人工作
- 之前的工作要么对于一对多翻译使用共享的encoder,对于多对多翻译使用特殊的attention机制,对于多对一翻译使用基于字符的输入,这些方法需要为每种语言精心设计encoder/decoder,限制模型扩展性。
- 后来有方法使用单一模型完成多语言翻译,但是这种方法将语言转化至同一空间,忽视语言特性。
- 有方法尝试重组参数共享(reorganizing parameter sharing)
- 设计语言特异的参数生成器(designing language-specific parameter generators)
- 解耦多语言编码(decoupling multilingual word encodings)
- 语言聚类(language clustering)
- 对于off-target的问题,有两种解决方法,一是引入跨语言正则化器(cross regularizers),例如alignment regularizer和consistency regularizer。二是通过回译产生平行语料(backtranslation),或者通过中间语言翻译(Pivot)
主要贡献
- 以一种更加便捷的、端到端的language specific方法,以及深化NMT网络来缓解模型容量问题;
- 采用随机在线backtranslation(ROBT)来缓解zero-shot translation中的off-target问题。
具体提出的方法
- 更深的网络模型,使用the depth-scaled initialization method去训练模型。
- (LALN)对于每个目标语言,使用前置token作为正则化的偏置
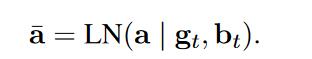
- (LALT)对于encoder端的输出,再接一个d*d的投影
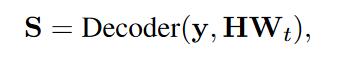
- (ROBt)首先训练一个多语言模型,再对此模型微调,对于每个batch里的每个平行语句对(x1,y1)来说,随机选取语言集T,将y1翻译到T中,形成新的平行语句对(x2,y1),(x3,y1)…..再去更新模型参数。

实验
训练设置
使用作者提出的OPUS-100训练集。总共包含了100种语言。由于是english-centric的,一共包含了99种language pair,一共有大约55M的训练样本,对于每一种language pair,都有2000条验证、测试数据。
另外,在zero-shot translation设置中,总共包含Arabic、Chinese、Dutch、French、German、Russian6个语种,共15个语言对。
One-to-Many translation
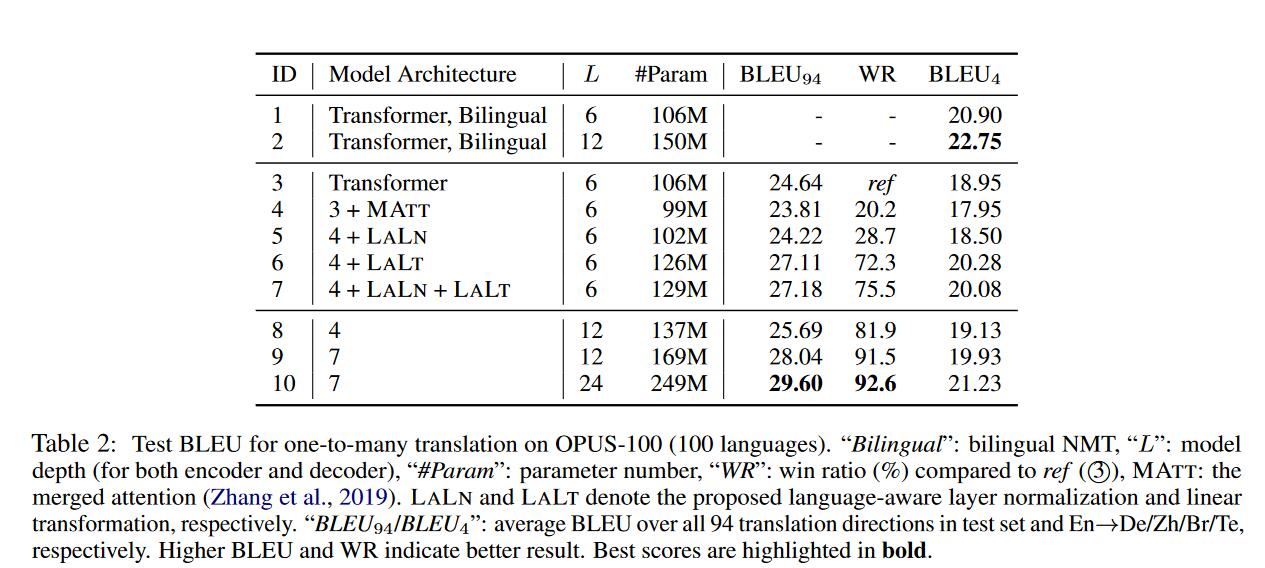
99个EN->X语言对上训练,得到的结论:
- LALT/LALN是有效的,表明丰富语言知觉(language awareness)能够减轻模型容量不足的缺点。
- 越深的模型越好
Many-to-Many translation
使用english-centric的语料共99*2个方向进行训练,再分别在EN->X、X->EN上评估。得到的几点结论:
- 在EN->X翻译上,多对多训练设置比一对多训练设置的表现来的差。可能的原因是模型容纳了更多的翻译方向,model capacity问题更明显。(table 2,3的Transformer行)
- 在X->EN翻译上,多对多训练设置比双语基线的表现来的好,说明多对多的训练设置,模型有较好的迁移能力。(table 4的1,2行)
- 在多对多翻译设置下。X->EN的提升要大于EN->X。这可能因为翻译方向上数据的分布不均,因为一半的数据都是->EN。
- LALT/LALN更偏向于目标语言的区分,因此对于EN->X提升大于X->EN
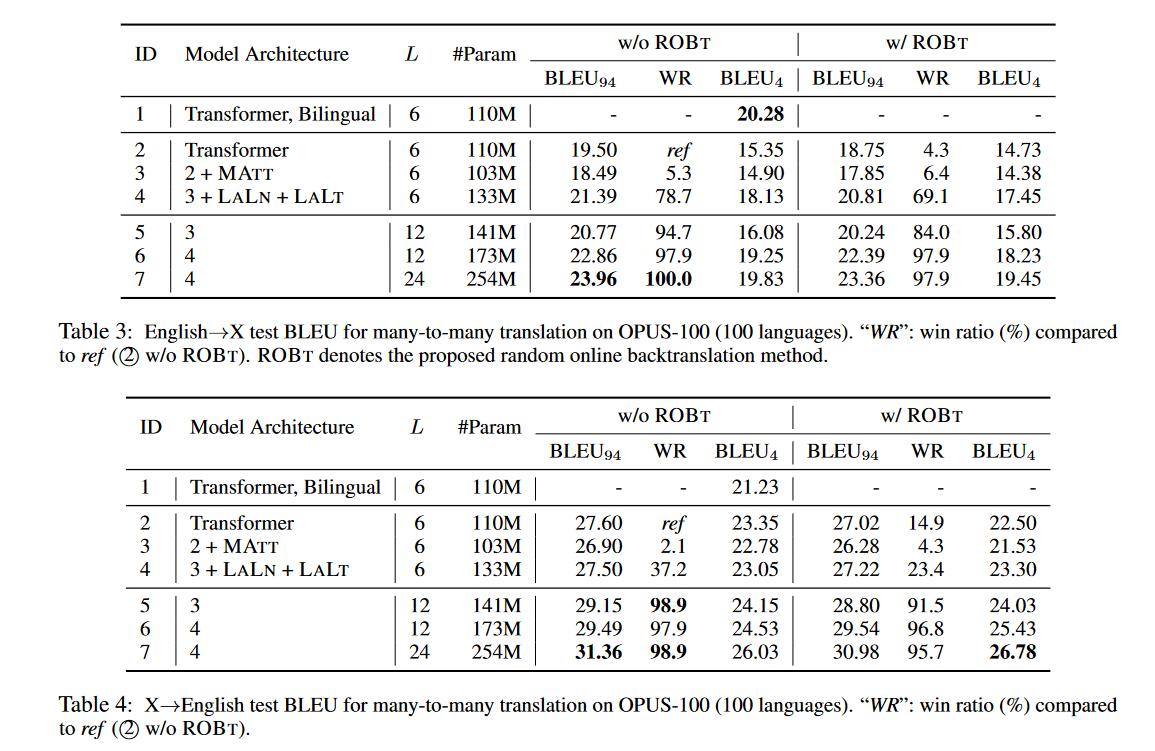
多对多翻译设置对不同资源语言的增益
不同语言对的句子数量是不一样的,这会影响到language-aware建模和更深的Transformer翻译。因此作者根据训练数据大小将测试语言对划分为三种形式,High (≥ 0.9M, 45), Low (< 0.1M, 18) and Medium (others, 31),得到以下结论
- 对于低资源语言来说,作者提出的方法在EN->X的翻译提升大于X->EN。
- 模型越深对于不同资源类型的语言和不同翻译方向上都更好。
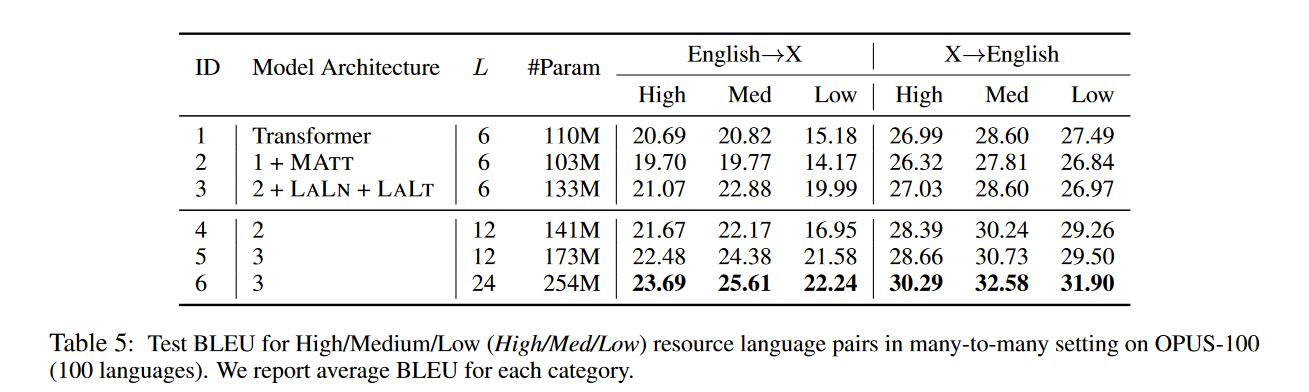
在Zero-shot上的结果
之前的工作发现在多语言模型上进行zero-shot翻译也即未在训练集出现的翻译方向上表现很差,作者经过实验得到以下结论:
- 模型容量不是表现差的主要原因,增大模型容量的性能提升也很少(第2,6行)
- zero-shot上结果很差的主要原因是off-target问题。
- 使用ROBt方法在zero-shot上会有更大的提升,并且off-target问题得到改善。但同时在非zero-shot上也有性能微降(在其他论文中也发现了这个问题)
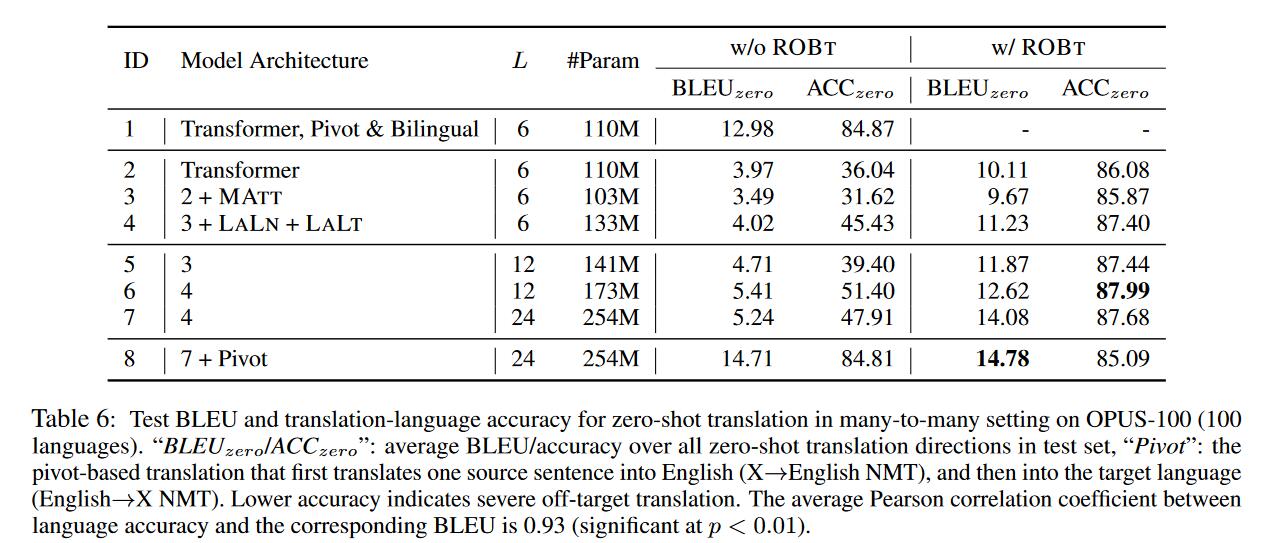
ROBt的探究
- ROBt能够加快模型收敛,在几千步就完成。
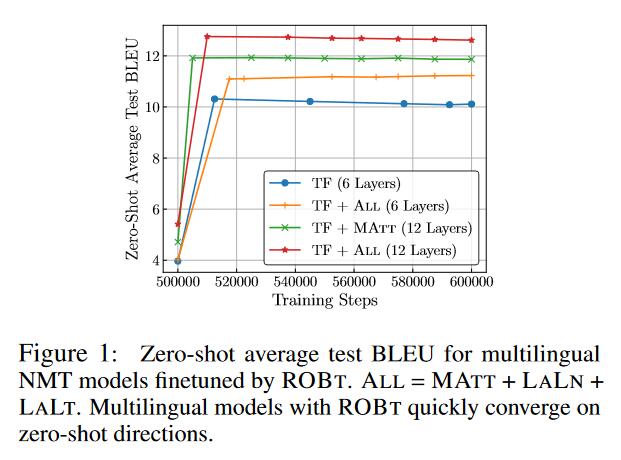
- 选择ROBt中的语言集合很关键,缩小集合范围能少量提升性能。

结语
作者为了解决多语言模型容量的问题使用了更深的模型架构和语言感知的模型(language-aware),并且提出random online backtranslation algorithm(ROBt)以解决zero-shot中的off-target问题。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 樱岛何处有麻衣!
 alipay
alipay