Improving Zero-Shot Translation by Disentangling Positional Information
引言
多语言翻译(NMT)在一个单独的模型中学习不同翻译方向的语句对,得到的模型能够直接在未知的翻译方向之间进行翻译。因此对于这种Zero-shot(在没有或很少训练语句对的翻译方向)翻译来说,是很有用的。首先不需要一个中介语言来辅助翻译,减少了一半推理时间和误差传播。其次不要求所有翻译方向具有大量的平行语句对语料,如果要实现N种语言之间互译的话不需要N^2数量级的方向上的语句对。最后对于模型来说,Zero-shot希望模型习得语句的中间表示,这两点对于低资源语言的翻译益处很大。
但是Zero-shot翻译的质量有待大幅提升,先前的工作发现其实标准的Transformer可能并没有真正习得不同语言对之间的翻译关联。在训练的时候学到的是将原句子以某种形式编码,这种形式便利了有监督情况下的目标语言的翻译,也就是编码成的中间表示其实关联着已知目标语言。但是对于Zero-shot翻译来说,很多翻译方向并不在训练中出现。decoder端的输入分布对于decoder来说是没有见过的,不可避免地造成性能下降。理想情况下,我们希望模型能够习得language-agnostic的中间表示,只要是在模型中训练过的target language,不管输入啥源语言都能根据这个中间表示翻译。
所以,我们似乎有了一个新的方向,就是统一不同语言版本encoder端输出的中间语言表示。这里来观察一个例子。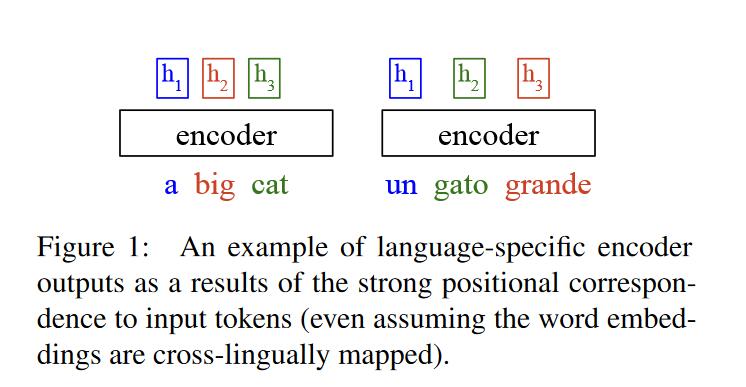
观察encoder端的输出,输出向量紧紧关联于原句子对应位置的tokens(以下称为位置关联)。但是对于同一句话的不同语言版本经encoder输出,我们希望它是尽可能和语言无关的。因此需要encoder端对词语的排序有较大自由度,允许输出向量重排。
沿着这条路作者有三点主要贡献:
- 实验证明位置关联确实会妨碍zero-shot翻译。移除了encoder layer中间一层的残差连接能够在zero-shot翻译上效果提升。
- 提出的模型易集成新语言,使得新语言和之前训练过的语言能够翻译,即使是zero-shot情况下。
- 深入分析了模型的中间输出,发现提出的方法有助于创造在token级别和句子级别上语言独立的表示。
消除位置关联信息
虽然Transformer encoder的编码有利于上下文嵌入和序列标注,但是encoder端的输入和输出在位置上仍然具有很强的关联,没办法做到”any input language, same representation”。对于不同语言相同语义的句子来说,编码后的序列长度和词序是会变化的。针对位置关联来说,可能的两种原因是残差连接和编码器自注意力对齐(encoder self-attention alignment)。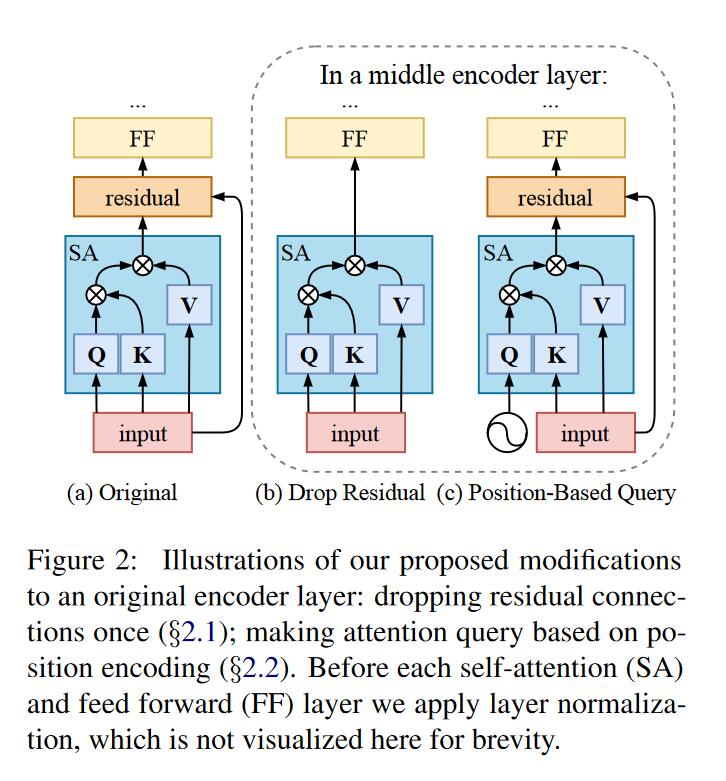
修改残差连接
在encoder layer中的两个子层都有残差连接,这种残差连接会导致输出和输入对应位置绑定。为了减轻这种影响,作者只在一层encoder layer中的一个multihead attention layer不使用残差连接。
基于位置的自注意力查询
之前的实验表明在自注意力层的NxN注意力权重中对角线的权重都是较大的,因此输出中对应位置的输入会占较大部分,造成了输入输出在位置上相关联。从源头看,造成对角线权重较大的原因是Q,K来源于相同向量,虽然经过不同的投影,但是还是较为相似。为了减少Q,K相似性,使用一组正弦位置编码代替Q(sinusoidal positional encodings,为啥用这种操作?),并且为了避免和K中就有的位置信息相似(注意encdoer的输入其实是加入位置信息的,这种信息会保留至K)。因此使用特定的波长(wave length),这个波长不同于起始编码加入的位置信息。此外,在得到真正Q的投影偏置中也使用了波长为100的位置编码(positional encoding with wave length 100.)。
variational dropout
作者使用variational dropout,和标准的dropout的差别是每层的dropout不是随机的而是固定的。作者认为这种方法能够通过
实验
训练细节
训练数据包括高资源语言和低资源语言,训练翻译方向是X<->EN,在测试时候是非英语的zero-shot翻译。模型为5层encoder,decoder的Transformer,对于较大的Europarl-full数据集使用8层。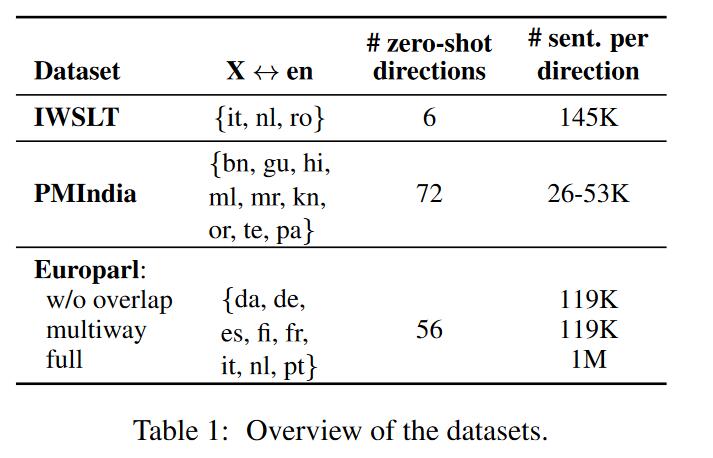
实验结果
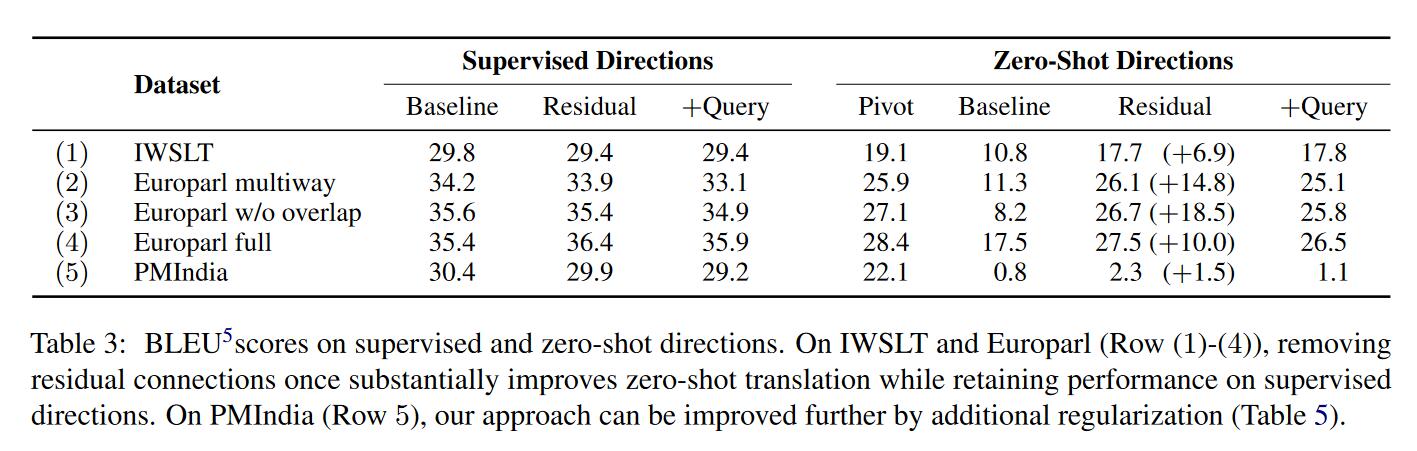
几点结论:
- 在zero-shot翻译上,修改残差连接是很有效的,在Supervised Directions也能和基线模型持平,但是Query的方法就不怎么有效。所以这种位置关联主要来源于残差连接。
- 观察第2,3行,得到的结论是训练数据越多样越好。第2行使用的是多平行句子作为数据集,第3行是没有重叠的数据。并且在zero-shot翻译上,修改残差连接更能有效利用更多样的数据。
- 在zero-shot翻译上,Pivot方法也是非常有效的,和Residual的结果较为接近,但是在计算资源有限的情况下比较难以应用。
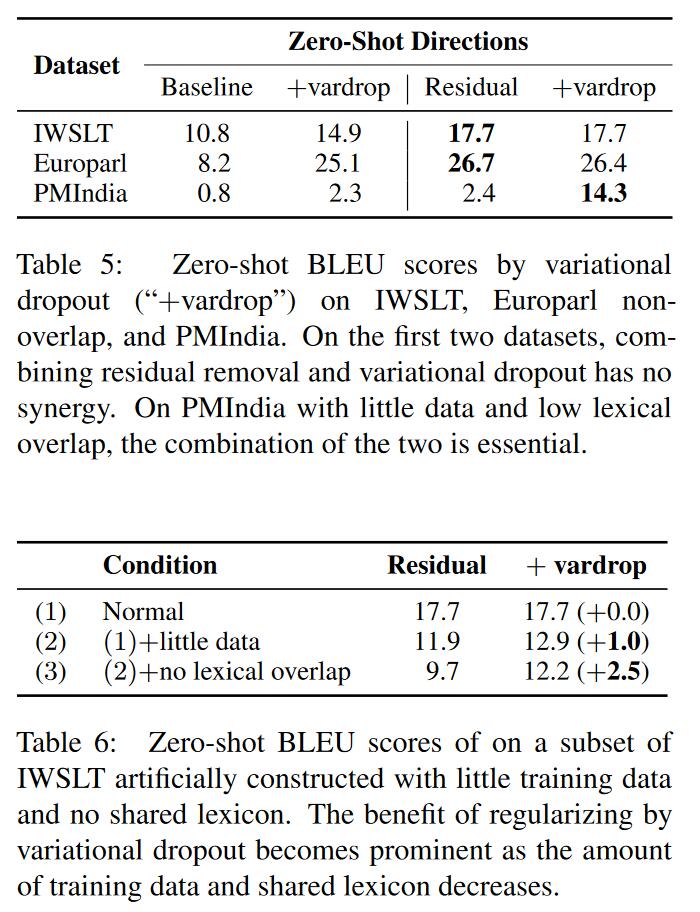
- 在句子数量较少,语言种类较多(尤其是lexical overlap较少)的数据集如PMIndia,修改残差连接的方法在zero-shot上的翻译很差,因此作者结合了variational dropout,发现效果有很大提升。但相较于Pivot方法来说还是差距很远,8左右。
为了查看模型的扩展性,因此作者加入新的语言,具体的方法是使用之前的模型在包含“新语言-英语”的数据集上微调,并且在“新语言-非英语语言”进行测试。从结果可以看到,baseline其实过拟合了“新语言-英语”翻译方向,导致在zero-shot翻译方向上很差,作者提出的模型则有更好的泛化性,在原有翻译方向上也不错,在zero-shot上有较大的性能提升。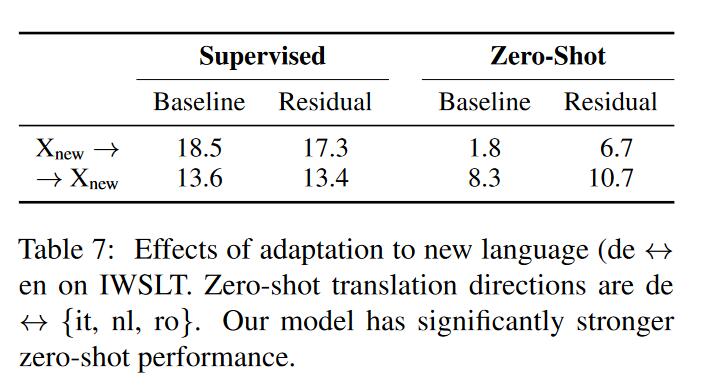
实验分析
检验位置关联
为了探索Residual方法是否真的减弱了位置关联性,作者训练一个分类器,将encoder输出向量映射至词汇表空间(Token ID)或者一句话timesteps空间(Position ID),发现Residual的方法确实会降低位置关联程度。再对encoder的每一层输出进行比较(更直观体现Residual方法),发现在使用Residual的层相关性会立刻降低。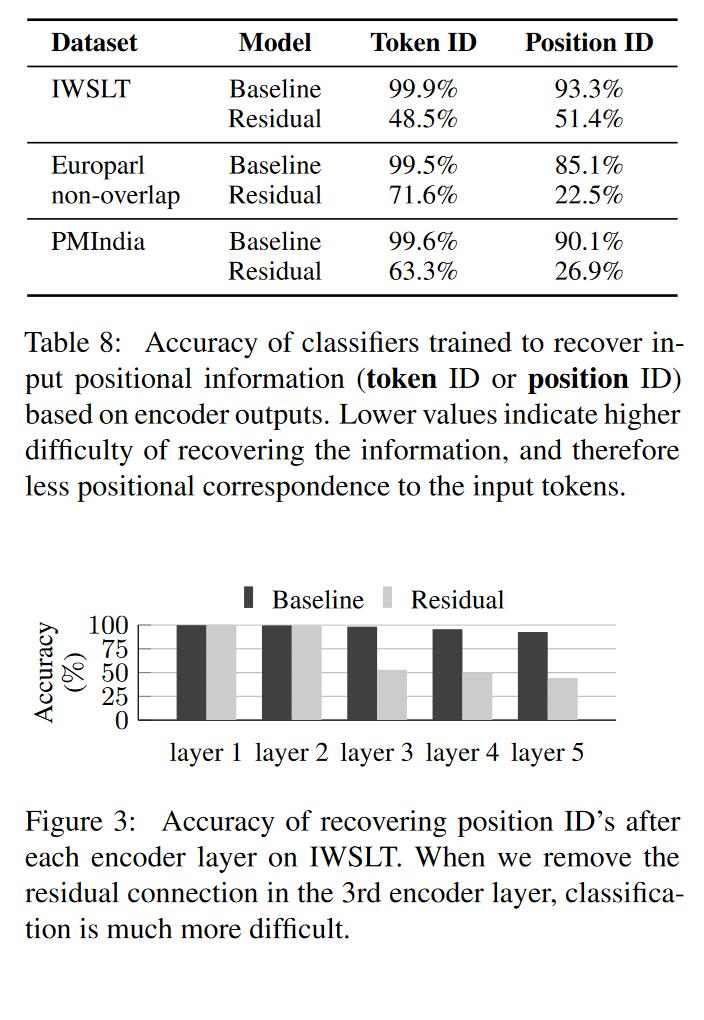
检验语言独立性
为了探索Residual方法是否产生了语言无关的表示,作者使用SVCCV,Language Classification Accuracy两种方法,从token和sentence两种角度分析了不同语言在encoder端的输出是否相似,或者每一层的输出是否相似。(其中SVCCV将输出平均池化然后分析相似度,后者将输出分类到语言类别空间,分的越差说明越相似。)Zero-shot中直接翻译的优势
作者探讨了Zero-shot直接翻译相较于Pivot的优势,除了只需要一次翻译外,Zero-shot的翻译可能更地道,更符合语法。使用固定的/可学习的位置嵌入
作者分析了位置嵌入对最后结果的影响,发现作者提出的方法对位置嵌入的形式是鲁棒的。
总结
作者认为encoder部分混杂了源语言词序的特点,这种位置关联特点影响了跨语言泛化能力,从而在zero-shot上性能差,作者提出了移除残差连接的方法减轻这种位置关联并在zero-shot上取得很好的性能。
 alipay
alipay