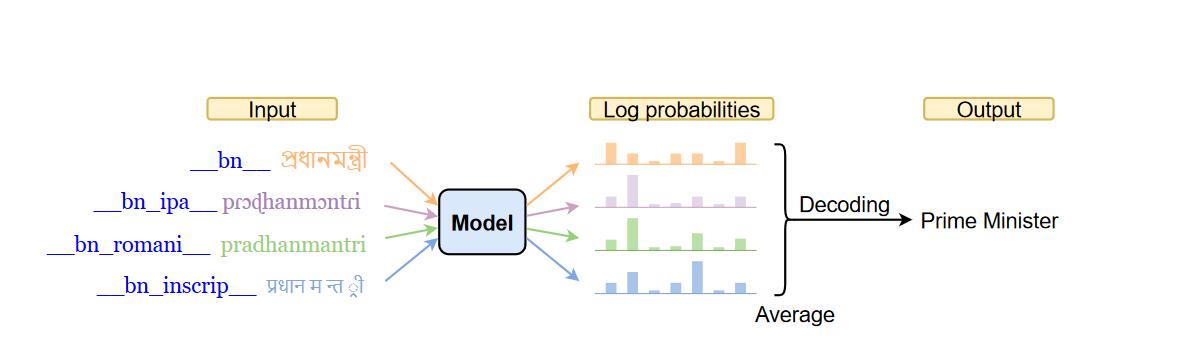
Multilingual Neural Machine Translation with Deep Encoder and Multiple Shallow Decoders
引言
目前很多多语言翻译的模型使用的是encoder-decoder模型,如果加深两端的网络深度可以提高翻译的性能。举例子来说,在many-to-one的翻译设置中增加encoder的深度会提高翻译质量,可能的解释是encoder端的参数体量大了能记住更多的源语言特征。但是对one-to-many来说,增加decoder端的参数会使得推理变慢。因此在这里就会有一个网络深度和模型性能、推理速度的权衡设计。之前的论文Deep encoder, shallow decoder: Reevaluating the speed-quality tradeoff in machine translation.提出了一种基于Transformer的模型——a deep encoder and a shallow decoder (DESD)。但这在one-to-many中会使得性能下降,可能是因为decoder端参数不足以为多个目标语言建模。因此为了能又快又准翻译,作者使用multiple shallow decoders,每个decoder对应于一类目标语言。其中作者探索了多种decoder-目标语言对应关系。
主要贡献
- 设置多种不同层数的DESD模型方案,在双语翻译和多语言翻译任务中权衡比较翻译速度(tokens/每秒)和准确性(BLEU)。
- 在
many-to-one翻译中,多语言DESD模型以1.8x更快的平均推理加速比得到与基线模型同等的表现(模型参数量相当) - 在
one-to-many翻译中,提出了shared encoder and multiple shallow decoders(DEMSD),得到1.8x更快的平均推理加速比,并且翻译质量更好。
多语言DESD模型的翻译速度和性能权衡
语料集
- ML50,49种语言<->英语,两亿句子对。
- TED8-Related,4种低资源语言,4种高资源语言。其中可以分为4个语言族,每个族2种语言
- TED8-Diverse,8种语言,不考虑语言之间相关性。
结果
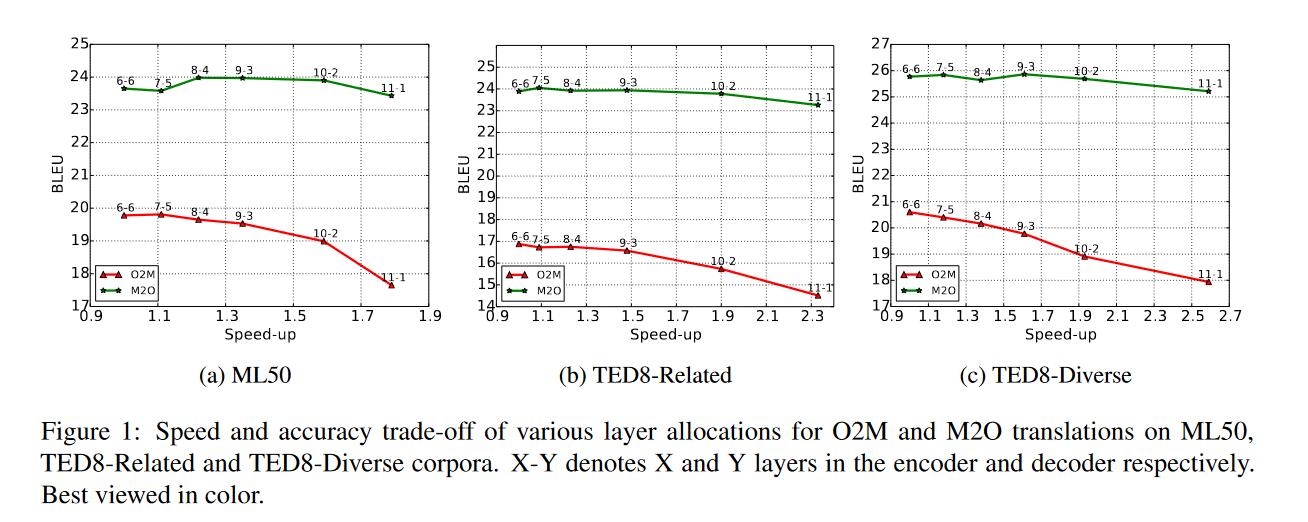
- 多于多对一翻译来说,减少了decoder端的层数其实对性能没有多大影响。这就说明其实对于decoder端,建模学习一种目标语言所需要参数量是很少的,也有可能是因为deep encoder更好地学习到了源语言,给出了更鲁棒的中间表示。
- 对于一对多翻译来说,当decoder端层数减少时性能会有明显下降。尤其是只有一两层时,在三个数据集上都是如此的趋势。这说明decoder端的参数量要和目标语言数量匹配(好奇1-11,2-10这样的层会是怎么样的效果)
- 一对多翻译的结果其实都是远不如多对一,这可能和参数量无关,而是需要一种更有效的模型架构将一映射到多。(个人看法)
Deep Encoder and Multiple Shallow Decoders(DEMSD)
既要保持推理速度比较快又要性能比较高的话,前者一定要求decoder端层数少,后者可以减少decoder端所要表示的语言数量。有一种方法就是对于不同语言集对应一个shallow decoder。作者讨论了以下几种对应方法:
- 最简单的放法就是每种语言一个decoder,(EACH)
- 随机语言集合划分到一个decoder,每个decoder的语言集合大小相同,作者随机取三次求平均。(RAND)
- 根据语言特征,每种语系一个decoder。(FAM)
- 使用经典前置token的方法,将训练好的模型前置token抽取出来,每个token对应一种语言,根据token将语言分类(聚类?),然后为每一类语言分配一个decoder。(EMB)
- 上一种方法的缺点是需要预训练一个模型,然后再找这种对应关系,比较繁琐。希望寻找一种方法能够再训练过程中自动分配。(ST)
第5点的数学说明:在给定一个共享的encocder,$E$和N个decoders,$D=[D_1,D_2,…,D_N]$。对于一个源语言$L$,模型要先找到对应的一个decoder,$D_i$。再通过这个解码器得到解码预测的句子。整体的概率公式为$\log p(y|x,E,D_i)$,$y,x$分别是输出输入的句子。那么怎么找到对应的序号$i$呢?通过对语言$L$对应在模型中的具体向量$L_e$和decoder的条件概率建模。也即对于给定$L_e$,选择条件概率最大的decoder。公式为$i={\arg\max}_j\ p(j|L_e)$。希望模型能够学习到给定$L_e$,每个decoder的概率分布。但是因为argmax目前的形式是不可微的,也就无法求导更新参数。因此使用Gumble-Softmax作为argmax的一种可微形式。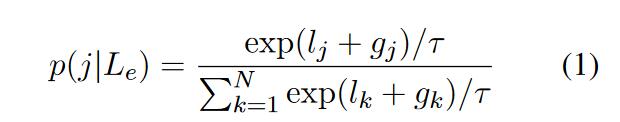
最后,在训练时要计算每个encoder的输出token概率分布加和。在推理时只需要选择$P(i|L_e)$最大的decoder。
实验结果
作者使用多个1层或2层的decoders,在三个数据集上进行了one-to-many实验。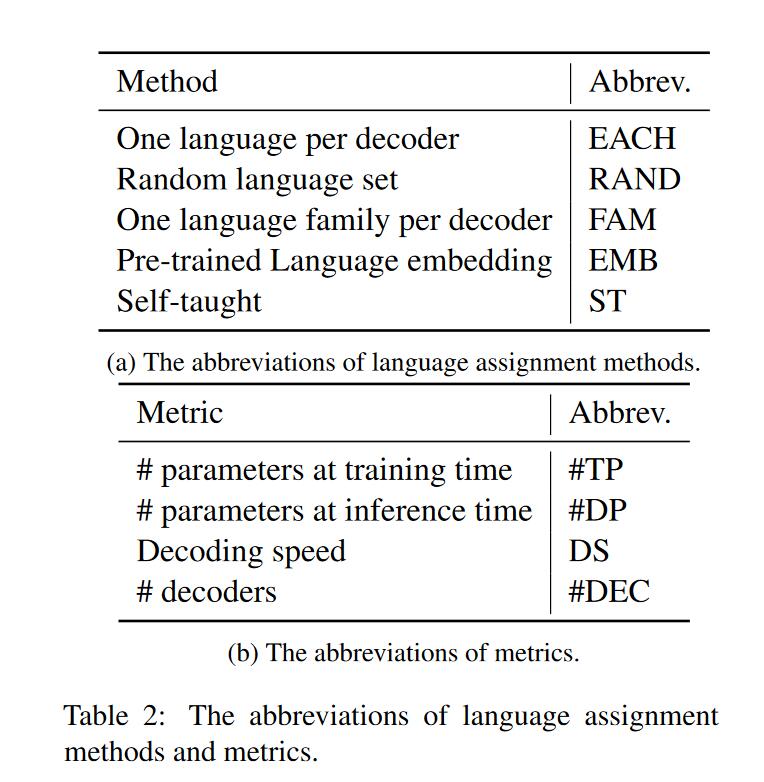
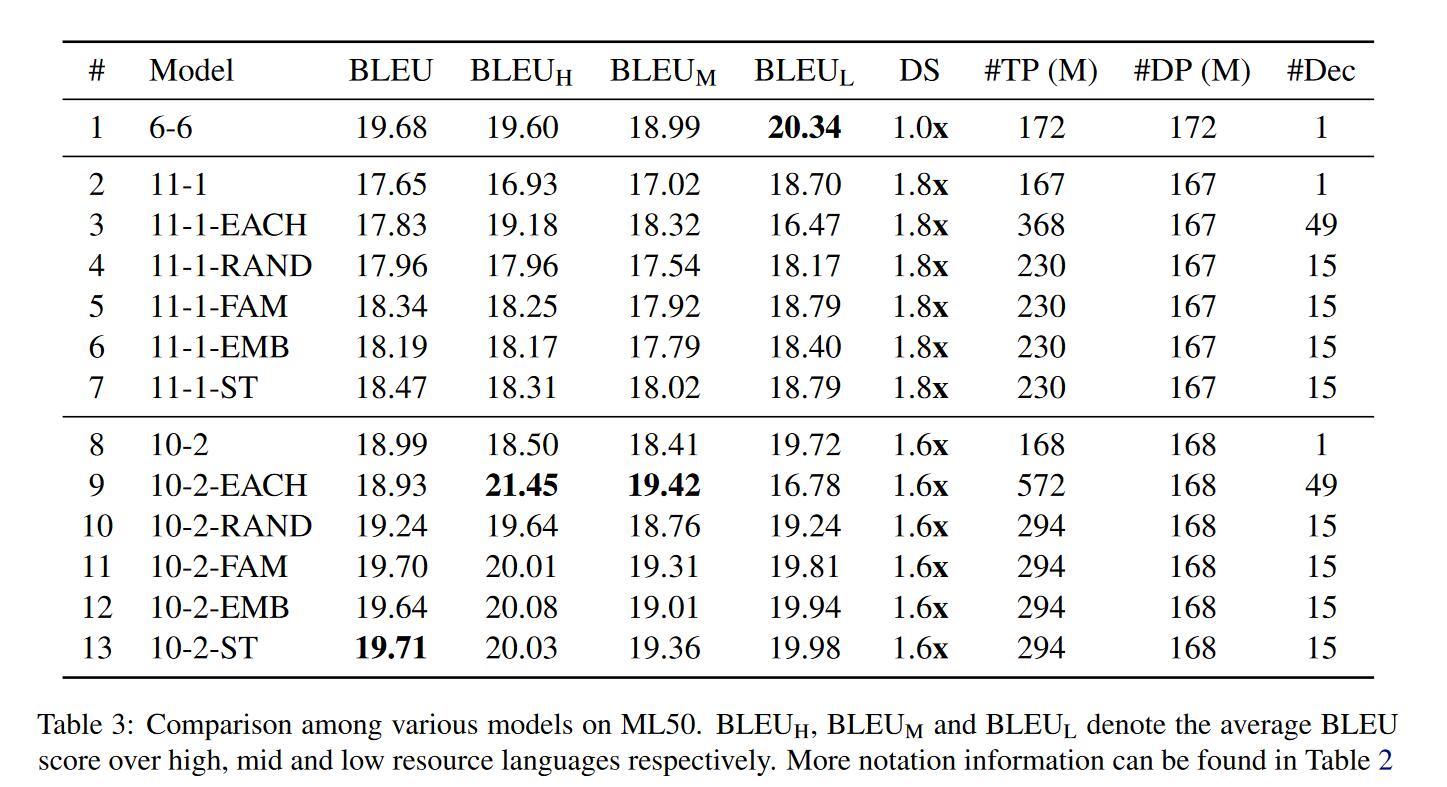
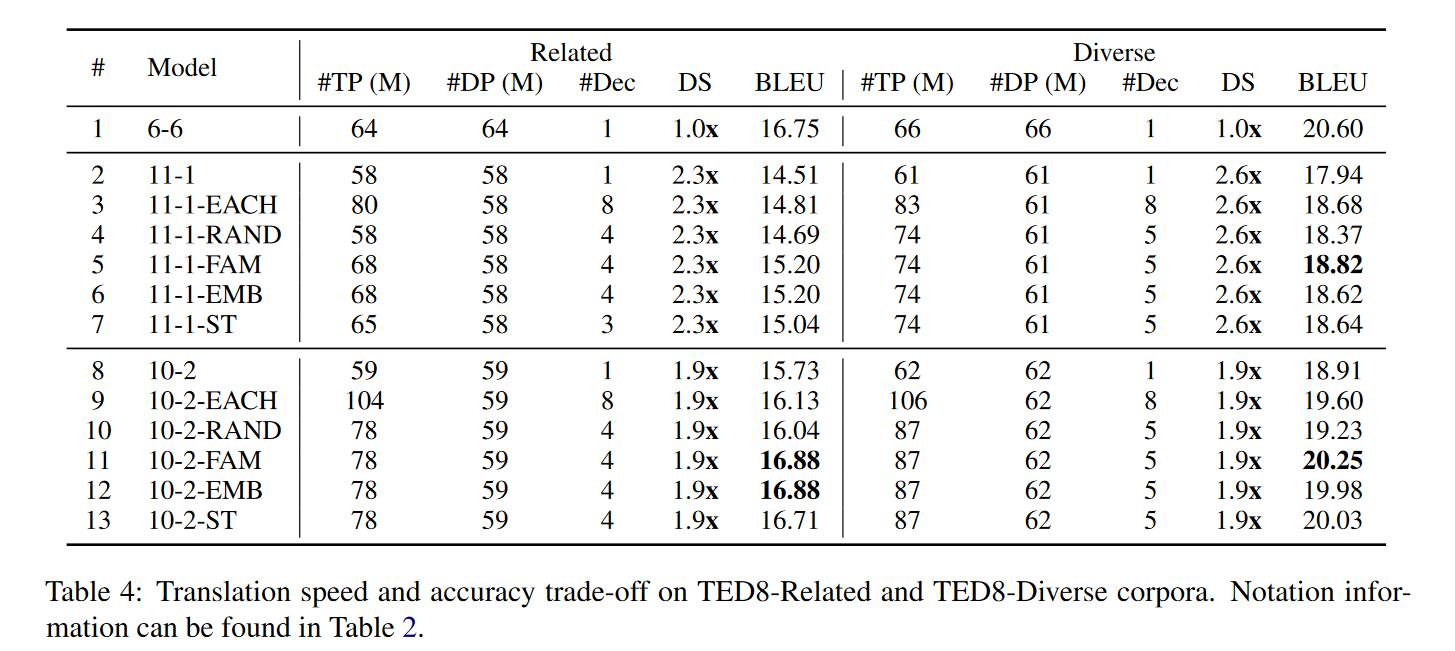
- 对于(EACH)来说,这种方法在中高资源语言中获得更好的性能,但是在低资源语言中表现很差(与第二行对比)。在高资源语言中表现好是因为可能没有负面的迁移学习干扰,并且模型容量比较大,容易习得特征。在低资源中表现不好,还是表明一两层的decoder没办法学习到鲁棒的表示。
- 对于(RAND)来说,其实性能有小小的提升,这可能是因为一个语言集合中有相似的语言,迁移学习有用。增加少量语言数量性能还是会增加的,证明decoder端其实有个最多能接受多少语言数的阈值。
- 对于(FAM)来说,ML50,TED8-Related和TED8-Diverse分别划分了15,4,5个语言族。实验证明确实能够提升性能减少推理时间,尤其是对2层的decoder来说性能更好。相同语言之间的迁移学习对性能提升有很大帮助。
- 对于(EMB)来说,首先在将多种语言分类时就发现其实划分的结果和语言族划分的结果相同或相近,因此结果也和FAM相似。
- 对于(ST)来说,这种方法既不需要知道语言族,也不需要提前训练好一个模型。从BLEU上看,这种方法也能得到较好的结果,也是有效。
扩展分析
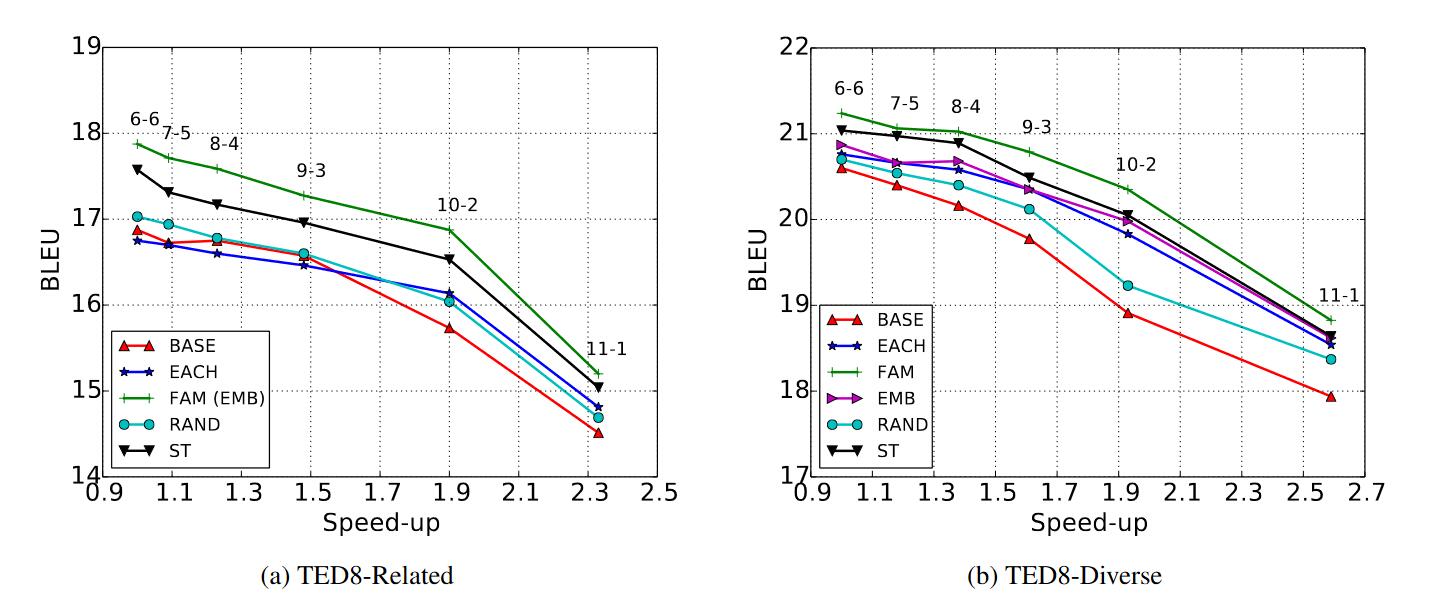
- 同样和之前一样有相同的趋势,decoder层数越少解码越快,但是性能越差。
- 使用10-2FAM、EMB方法在层数较少的情况下和6-6 baseline性能相似,但是解码快了近2倍。
总结
之前的方法DSED在解码速度上有提升,但是在一对多翻译上性能很差,为了尽可能提高这种方法性能,作者提出了DEMSED,其中每一个decoder对应一类语言集,作者讨论了不同的对应方法,将相近的语言族对应一个decoder能够达到更快的1.8倍解码速度,其性能还能匹配标准的基线模型。
 alipay
alipay